این مقاله انگلیسی ISI در نشریه الزویر در 9 صفحه در سال 2014 منتشر شده و ترجمه آن 24 صفحه میباشد. کیفیت ترجمه این مقاله ویژه – طلایی ⭐️⭐️⭐️ بوده و به صورت کامل ترجمه شده است.
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی
|
|
| عنوان فارسی مقاله: |
شبکه های عصبی مصنوعی و تشخیص گفتار دیاستولیک: شناسایی بهترین عملکرد از پارامترهای MFCC و مطالعه یک رویکرد مستقل سخنران |
| عنوان انگلیسی مقاله: |
Artificial neural networks as speech recognisers for dysarthric speech: Identifying the best-performing set of MFCC parameters and studying a speaker-independent approach |
|
|
| مشخصات مقاله انگلیسی (PDF) | |
| سال انتشار | 2014 |
| تعداد صفحات مقاله انگلیسی | 9صفحه با فرمت pdf |
| رشته های مرتبط با این مقاله | مهندسی کامپیوتر |
| گرایش های مرتبط با این مقاله | مهندسی الگوریتم ها و محاسبات و هوش مصنوعی |
| مجله | انفورماتیک مهندسی پیشرفته – Advanced Engineering Informatics |
| دانشگاه | گروه مهندسی نرم افزار، دانشکده کامپیوتر و فناوری اطلاعات، دانشگاه مالایا، مالزی |
| کلمات کلیدی | شبکه های عصبی مصنوعی، MFCC، دیزارتیا، تشخیص گفتار خودکار |
| شناسه شاپا یا ISSN | ISSN 1474-0346 |
| رفرنس | دارد ✓ |
| لینک مقاله در سایت مرجع | لینک این مقاله در نشریه Elsevier |
| نشریه | الزویر – Elsevier |
| مشخصات و وضعیت ترجمه فارسی این مقاله (Word) | |
| تعداد صفحات ترجمه تایپ شده با فرمت ورد با قابلیت ویرایش و فونت 14 B Nazanin | 24صفحه |
| ترجمه عناوین تصاویر و جداول | ترجمه شده است ✓ |
| ترجمه متون داخل تصاویر | ترجمه نشده است ☓ |
| ترجمه متون داخل جداول | ترجمه شده است ✓ |
| درج تصاویر در فایل ترجمه | درج شده است ✓ |
| درج جداول در فایل ترجمه | درج شده است ✓ |
| درج فرمولها و محاسبات در فایل ترجمه به صورت عکس | درج شده است ✓ |
| منابع داخل متن | به صورت عدد درج شده است ✓ |
- فهرست مطالب:
چکیده
1- مقدمه
2- نگاهی به گذشته
3- روش ها
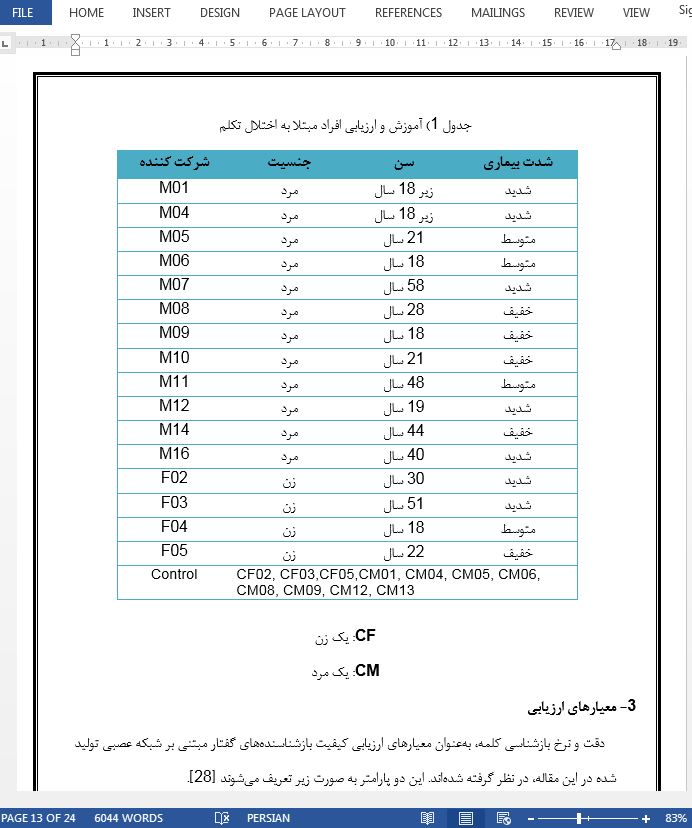
الف – مواد و شرکت کنندگان
ب- مدل ASR مبتنی بر شبکههای عصبی مصنوعی برای کاربران مبتلا به اختلال تکلم
ج- معیارهای ارزیابی
4- آزمایشها و نتایج
5- آزمایش1: شناسایی بهترین مجموعه از پارامترهای MFCC
6- آزمایش2: ASR مبتنی بر شبکه عصبی مستقل ازگوینده
7- بحث
8- نتیجه گیری
- بخشی از ترجمه:
نتیجه گیری
در این مقاله ما کاربرد شبکههای عصبی مصنوعی را در یک مدل ASR مستقل از گوینده، مطالعه کردیم. علاوه بر این، چند بازشناسنده گفتار متکی به گوینده مبتنی بر شبکه عصبی را برای کاربران مبتلا به اختلال تکلم، ارائه دادیم و به طور مفصل نتایج را مقایسه کردیم. هدف، تعیین بهترین مجموعه از ویژگیهای اصلی MFCC است که بتوانند ویژگیهای آوایی را نمایش دهند؛ که این نمایش میتواند به وسیلۀ یک سیستم ASR مبتنی بر شبکه عصبی طراحی شده برای اشخاص مبتلا به اختلال تکلم، استفاده شود. نرخ بازشناسی کلمه و دقت ارزیابی مدلهای ASR پیشنهادی، مورد بررسی قرار گرفتند. نمونههای گفتاری اشخاص گنگ برای هر یک از سطوح مختلف اختلال تکلم، به وسیلۀ سیستمهای ASR مستقل از گوینده پیشنهادی، به طور جداگانه ارزیابی شدند. دادههای گفتاری افراد مورد ارزیابی، برای آموزش بازشناسندههای گفتار مستقل از گوینده، به حساب نیامدند. این محروم سازی دادههای گفتاری افراد مورد ارزیابی، تعمیمپذیری مدلهای پیشنهادی را تصویب میکند.
نتایج نشان میدهد که 12 ضریب اصلی کپسترم، میتواند به عنوان بهترین مجموعه از ویژگیهای آوایی MFCC به منظور آموزش یک سیستم ASR مبتنی بر شبکه عصبی، انتخاب شود. WRR مدل ASR مستقل از گوینده آموزش دیده با 12 ضریب اصلی کپسترم، به میانگین 38/68 درصدی رسید. این مدل هم-چنین برای گفتار گویندگان سالم پیشبینی نشده، WRR 07/98 درصدی، ارائه داد. بیش ترین WRR برای مدلهای ASR متکی به گوینده، 95 درصد بود.
- بخشی از مقاله انگلیسی:
6. Conclusions
In this paper we studied the application of ANNs in an SI ASR model for individuals with dysarthria. In addition, several SD ANN-based speech recognisers for users with dysarthria were provided, and the results were compared in detail. The purpose is to investigate and to ascertain the best MFCC-based feature set that can represent dysarthric acoustic features; the representation is then used by an ANN-based SI ASR system designed for individuals with dysarthria. The performance of the proposed ASR models was measured in terms of word recognition rate and accuracy of evaluation. Speech samples of the subjects with speech disabilities were evaluated by the proposed SI ASR systems for each dysarthric severity level separately. The speech data of the evaluation subjects were not included for the training of the SI speech recognisers. This exclusion of speech data of the evaluation subjects allows the generalisability of the proposed models to be evaluated.
The results show that mel cepstrum with 12 coefficients can be selected as the best set of MFCC acoustic features in order to train an ANN-based ASR system for speakers with dysarthria. The WRR of the dysarthric SI ASR model, trained with mel cepstrum including 12 coefficients achieved an average of 68.38%. It also produced 98.07% WRR for the speech of unanticipated speakers without speech disabilities. The highest WRR of speaker-dependent ASR models was 95%.
|
تصویری از مقاله ترجمه و تایپ شده در نرم افزار ورد |
|
|
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی
|
|
| عنوان فارسی مقاله: |
شبکه های عصبی مصنوعی و تشخیص گفتار دیاستولیک: شناسایی بهترین عملکرد از پارامترهای MFCC و مطالعه یک رویکرد مستقل سخنران |
| عنوان انگلیسی مقاله: |
Artificial neural networks as speech recognisers for dysarthric speech: Identifying the best-performing set of MFCC parameters and studying a speaker-independent approach |
|
|