این مقاله انگلیسی ISI در نشریه IEEE در 12 صفحه در سال 2019 منتشر شده و ترجمه آن 37 صفحه میباشد. کیفیت ترجمه این مقاله ویژه – طلایی ⭐️⭐️⭐️ بوده و به صورت کامل ترجمه شده است.
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی | |
| عنوان فارسی مقاله: |
قابلیت ارتجاعی چند سطحی برای پردازش جریان داده |
| عنوان انگلیسی مقاله: |
Multi-Level Elasticity for Data Stream Processing |
|
|
|
| مشخصات مقاله انگلیسی | |
| فرمت مقاله انگلیسی | |
| سال انتشار | 2019 |
| تعداد صفحات مقاله انگلیسی | 12 صفحه با فرمت pdf |
| نوع مقاله | ISI |
| نوع ارائه مقاله | ژورنال |
| رشته های مرتبط با این مقاله | مهندسی کامپیوتر |
| گرایش های مرتبط با این مقاله | رایانش ابری |
| چاپ شده در مجله (ژورنال) | نتایج بدست آمده در حوزه سیستم های موازی و توزیع شده – Transactions on Parallel and Distributed Systems |
| کلمات کلیدی | پردازش جریان، قابلیت ارتجاعی چند سطحی، آپاچی استورم |
| کلمات کلیدی انگلیسی | stream processing – multi-level elasticity – Apache Storm |
| ارائه شده از دانشگاه | دانشگاه گرنوبل آلپ، گرنوبل، فرانسه |
| نمایه (index) | Scopus – Master Journals List – JCR |
| نویسندگان | Vania Marangozova-Martin, Noël de Palma and Ahmed El Rheddane Univ. Grenoble Alpes |
| شناسه شاپا یا ISSN | 1045-9219 |
| شناسه دیجیتال – doi | https://doi.org/10.1109/TPDS.2019.2907950 |
| ایمپکت فاکتور(IF) مجله | 4.154 در سال 2019 |
| شاخص H_index مجله | 130 در سال 2020 |
| شاخص SJR مجله | 0.929 در سال 2019 |
| شاخص Q یا Quartile (چارک) | Q1 در سال 2019 |
| بیس | نیست ☓ |
| مدل مفهومی | ندارد ☓ |
| پرسشنامه | ندارد ☓ |
| متغیر | ندارد ☓ |
| رفرنس | دارای رفرنس در داخل متن و انتهای مقاله ✓ |
| کد محصول | 7421 |
| لینک مقاله در سایت مرجع | لینک این مقاله در سایت IEEE |
| نشریه آی تریپل ای | |
| مشخصات و وضعیت ترجمه فارسی این مقاله | |
| فرمت ترجمه مقاله | pdf و ورد تایپ شده با قابلیت ویرایش |
| وضعیت ترجمه | انجام شده و آماده دانلود |
| کیفیت ترجمه | ویژه – طلایی ⭐️⭐️⭐️ |
| تعداد صفحات ترجمه تایپ شده با فرمت ورد با قابلیت ویرایش | 37 (1 صفحه رفرنس انگلیسی) صفحه با فونت 14 B Nazanin |
| ترجمه عناوین تصاویر و جداول | ترجمه شده است ✓ |
| ترجمه متون داخل تصاویر | ترجمه شده است ✓ |
| ترجمه متون داخل جداول | ترجمه شده است ✓ |
| ترجمه ضمیمه | ندارد ☓ |
| ترجمه پاورقی | ندارد ☓ |
| درج تصاویر در فایل ترجمه | درج شده است ✓ |
| درج جداول در فایل ترجمه | درج شده است ✓ |
| درج فرمولها و محاسبات در فایل ترجمه | به صورت عکس درج شده است ✓ |
| منابع داخل متن | درج نشده است ☓ |
| منابع انتهای متن | به صورت انگلیسی درج شده است ✓ |
| فهرست مطالب |
|
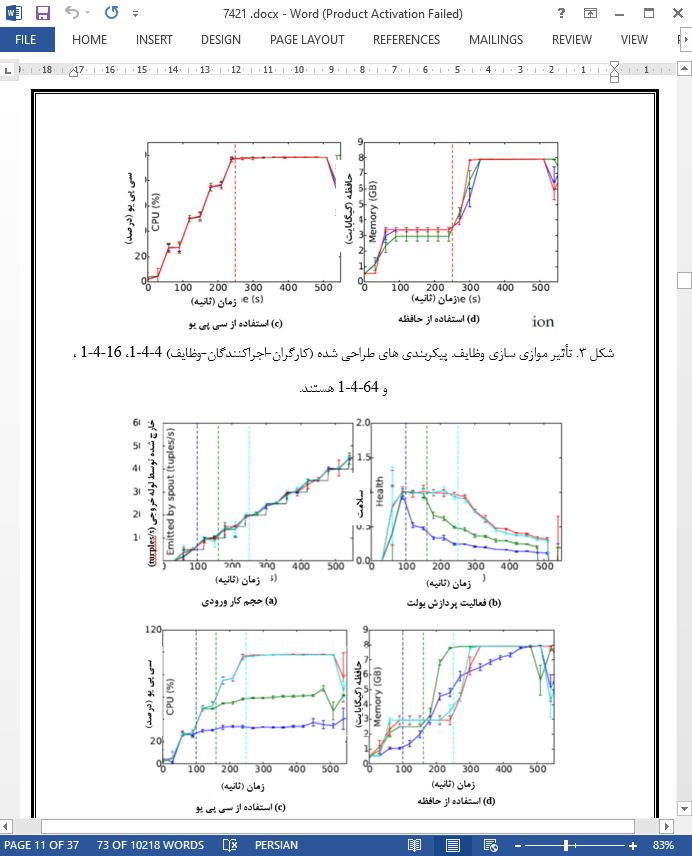
چکیده 1- مقدمه 2- انگیزش برای قابلیت ارتجاعی چند سطحی 2-1- مدل سیستم 2-2- معیارهای عملکرد 2-3- عملکردهای استورم 3- یک استراتژی برای قابلیت ارتجاعی چند سطحی 3-1- کنترل ارتجاعی 4- اجرا 5- ارزیابی تجربی 5-1- اپلیکیشن DDoS 5-2- قابلیت ارتجاعی واکنشی برای ارزیابی اپلیکیشن 5-3- قابلیت ارتجاعی فعال برای DDoS 5-4- اندازه گذاری منابع برای تحلیل داده آنلاین 6- مطالعات مرتبط 7- نتیجه گیری |
| بخشی از ترجمه |
|
چکیده مقاله حاضر به بررسی قابلیت ارتجاعی (الاستیسیته) واکنشی در محیط های پردازش جریان می پردازد که هدف عملکردی آنها تحلیل مقادیر بزرگی از داده هایی با نهفتگی پایین و حداقل منابع است. ما با کار کردن در زمینه آپاچی استورم، یک استراتژی مدیریت ارتجاعی را پیشنهاد می کنیم که میزان توازی مؤلفه های اپلیکیشن ها را تعدیل میکند و در عین حال، سلسله مراتب محفظه های اجرایی (ماشین ها، فرآیندها و نخ های مجازی) را بطور واضح حل میکند. ما نشان می دهیم که فراهم سازی نوع اشتباهی از محفظه ممکن است منجر به افت عملکرد گردد؛ بنابراین ما راه حلی را پیشنهاد می کنیم که ارزان ترین محفظه ها (با حداقل منابع) را فراهم می سازد تا عملکرد را افزایش دهد. ما متریک های نظارت خود را توصیف می کنیم و نشان می دهیم که چطور خصوصیات یک محیط اجرایی را مد نظر قرار می دهیم. ما یک ارزیابی تجربی با اپلیکیشن های دنیای واقعی را فراهم می سازیم که کاربردپذیری رویکرد ما را تأیید می کند.
مقدمه داده های بزرگ یک چالش در حوزه های مختلف سیستم محاسباتی است. داده های بزرگ در اینترنت اشیاء نیز وجود دارد و با تکثیر دستگاه های متصل، همراه با مقیاس فزاینده سیستم های کامپیوتری با عملکرد بالا رشد میکند و با فعالیت های اینترنتی و شبکه های اجتماعی رو به رشد، همراه است. این یک موضوع اصلی در کسب و کار هوش داده ای است. دو تکنیک اصلی برای پردازش داده های بزرگ وجود دارد: پردازش دسته ای و پردازش جریانی. در پردازش دسته ای، داده ها ابتدا در پایگاه داده های بزرگی ذخیره میشوند و بعداً پردازش می گردند؛ اینکار معمولاً با مدلهای برنامه نویسی مقیاس پذیری مانند Google’s MapReduce انجام میشود. با اینحال با اندازه رو به رشد داده ها، هزینه انتقال و ذخیره سازی آنها قابل جلوگیری نیست. بعلاوه در بسیاری از دامنه ها، چیزی که مهم است نگه داشتن داده های اولیه نیست بلکه تحلیل آنها در سریعترین زمان ممکن است تا اطلاعات ارزشمندی را ایجاد کنند. سیستم های پردازش جریانی برای حل این مسائل، بر واکنش پذیری و تحلیل داده ها به محض تولید شدن آنها، تأکید دارند. سالهای اخیر شاهد پیدایش راه حل های مختلفی از پردازش جریانی بوده است.
نتیجه گیری تمرکز مطالعه ما بر روی تأثیر محفظه های اجرایی مختلف بر عملکرد یک سیستم پردازش جریانی ارتجاعی است. ما سلسله مراتب محفظه های اجرایی (ماشین ها، فرآیندها و نخ ها) را بصورت واضح بررسی کرده ایم و نشان داده ایم که فراهم سازی آنها با هزینه های مختلفی انجام می شود. مهمتر اینکه ما نشان داده ایم که فراهم سازی نوع اشتباهی از محفظه ها میتواند سبب افت عملکرد گردد. |
| بخشی از مقاله انگلیسی |
|
Abstract This paper investigates reactive elasticity in stream processing environments where the performance goal is to analyze large amounts of data with low latency and minimum resources. Working in the context of Apache Storm, we propose an elastic management strategy which modulates the parallelism degree of applications’ components while explicitly addressing the hierarchy of execution containers (virtual machines, processes and threads). We show that provisioning the wrong kind of container may lead to performance degradation and propose a solution that provisions the least expensive container (with minimum resources) to increase performance. We describe our monitoring metrics and show how we take into account the specifics of an execution environment. We provide an experimental evaluation with real-world applications which validates the applicability of our approach.
INTRODUCTION BIg data is a challenge in various computing system domains. It is present in IoT with the proliferation of connected devices, grows with the increasing scale of high performance computing systems and is coupled with the expanding Internet and social network activities. It is a major topic in the data intelligence business. There are two major techniques to process big data: batch processing and stream processing. In batch processing, data is first stored in huge databases and is processed later, usually with scalable programming models such as Google’s MapReduce [1]. However, with the ever growing size of data, the cost of data transfer and storage becomes prohibitive [2], [3]. Moreover, in multiple domains, what is important is not to keep the initial data but to analyze it as fast as possible to produce valuable intelligence [4], [5]. To tackle these issues, stream processing systems put the emphasis on reactivity and analyze data as it is produced. Recent years have seen the emergence of multiple stream processing solutions [6], [7], [8], [9].
CONCLUSION The focus of our paper is on the impact of different execution containers on the performance of an elastic stream processing system. We have explicitly considered the hierarchy of execution containers (machines, processes and threads) and have shown that their provisioning comes at a different cost. More importantly, we have shown that provisioning the wrong type of containers may decrease performance. |
|
تصویری از مقاله ترجمه و تایپ شده در نرم افزار ورد |
|
|
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی | |
| عنوان فارسی مقاله: |
قابلیت ارتجاعی چند سطحی برای پردازش جریان داده |
| عنوان انگلیسی مقاله: |
Multi-Level Elasticity for Data Stream Processing |
|
|
|