گروه آموزشی ترجمه فا اقدام به ارائه ترجمه مقاله با موضوع ” خصوصیات عدم تجانس در سیستم های توصیه کننده ” در قالب فایل ورد نموده است که شما عزیزان میتوانید پس از دانلود رایگان مقاله انگلیسی و نیز مطالعه نمونه ترجمه و سایر مشخصات، ترجمه را خریداری نمایید.
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی
|
|
| عنوان فارسی مقاله: |
ویژگی های عدم تشابه در سیستم های توصیه گر |
| عنوان انگلیسی مقاله: |
Dissimilarity Features in Recommender Systems |
|
|
| مشخصات مقاله انگلیسی (PDF) | |
| سال انتشار | 2013 |
| تعداد صفحات مقاله انگلیسی | 8 صفحه با فرمت pdf |
| رشته های مرتبط با این مقاله | مهندسی کامپیوتر و فناوری اطلاعات |
| گرایش های مرتبط با این مقاله | مدیریت سیستم های اطلاعات، مهندسی نرم افزار، مهندسی الگوریتم ها و محاسبات، هوش مصنوعی و اینترنت و شبکه های گسترده |
| مجله | سیزدهمین کنفرانس بین المللی در داده کاوی – 13th International Conference on Data Mining |
| دانشگاه | یونان |
| کلمات کلیدی | سیستم های توصیه شده، ویژگی های ناهمگونی |
| شناسه شاپا یا ISSN | ISSN 2375-9232 |
| رفرنس | دارد |
| لینک مقاله در سایت مرجع | لینک این مقاله در سایت IEEE |
| نشریه آی تریپل ای | |
| مشخصات و وضعیت ترجمه فارسی این مقاله (Word) | |
| تعداد صفحات ترجمه تایپ شده با فرمت ورد با قابلیت ویرایش و فونت 14 B Nazanin | 23 صفحه |
| ترجمه عناوین تصاویر و جداول | ترجمه شده است |
| ترجمه متون داخل تصاویر | ترجمه نشده است |
| ترجمه متون داخل جداول | ترجمه نشده است |
| درج تصاویر در فایل ترجمه | درج شده است |
| درج جداول در فایل ترجمه | درج شده است |
| درج فرمولها و محاسبات در فایل ترجمه به صورت عکس | درج شده است |
- فهرست مطالب:
خلاصه
مقدمه
اجتماعهای کاربر از طریق شباهتهای جفتی
استخراج ویژگی مبتنی بر عدم تشابه
بکارگیری در توصیهگرهای مبتنی بر ویژگی
کارهای مرتبط
فریم کاری استخراج ویژگی عدم تشابه
ایجاد پروفایلهای کاربر
تخمین شباهتهای کاربر
تخمین ویژگیهای عدم تشابه
فریک کاری طبقهبندی
تبدیل Naive Bayes مبتنی بر اجتماع
لیبلگذاری نمونه
آزمایشات
توصیف دیتاست
طبقهبندیکنندهها بعنوان توصیهگرها
متریکهای ارزیابی
تشکرات
- بخشی از ترجمه:
VI نتیجه گیری و کار آینده
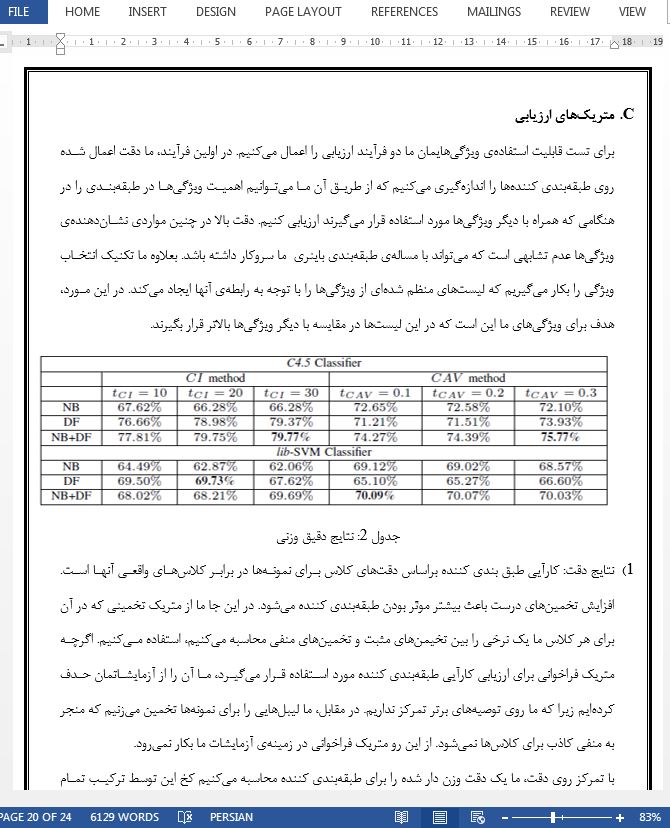
در این مقاله ما فریم کاری استخراج ویژگی عدم تشابه را معرفی کردیم که این از طریق نمایش آیتمها با ویژگی های جدید صورت گرفت. که وقتی در کار طبقهبندی مورد استفاده قرار گرفت، این نمایشهای غنی شده در کشف آیتمهای ارجح موثر هستندريال زیرا انها ممنجر به کارآیی بهبود یافتهای در دقت شدهاند. نتایج نشان داده شده از طبقهبندیهای اعمال شده و تکنیکهای انتخاب ویژگی صحت کاربرد ویژگیها ما را نشان میدهد.
در کارهای آینده ما علاقمند به مقایسهی ویژگیهایمان با تلاشهای تحقیقاتی جدید مانند تکنیکهای فاکتوری کردن ماتریس [17] میباشیم. چنین مطالعات قیاسی باعث بهبود اهمیت کار ما می شود. بعلاوه با در نظر گرفتن پیچیدگی محاسباتی فریم کاری استخراج ویژگی، ما برای فراهم سازی پیادهسازی توزیع شده از طریق کاهیش زمان اجرا برنامه داریم. در نهایت فریم کاری پیشنهاد شده میتواند برای فراهم سازی توصیه در زمینهی شبکههای اجتماعی بکار گرفته شود. با در نظر گرفتن اجتماع کاربران، ما میتوانیم ویژگیهای عدم تشتابه را برای آیتمهایی که آنها نظرشان را درباره اش گفتهاند محاسبه کنیم. سپس، این ویژگی ها می تواند منجر به اختلاف بین کاربران شود که می تواند برای جداسازی آنها در دو قطب استفاده شود. یک قطب شامل کاربران با وزنهای غیرمستقیم کوچک (به عنوان مثال کاربران با هم اندیشی) است، در حالی که قطب دیگر شامل افرادی با وزنهای متمادی بالا (به عنوان مثال کاربر متضاد) می باشد. برنامه هایی که به دنبال تعادل بین دقت و تنوع می توانند از هر دو قطب کاربران استفاده کنند.
- بخشی از مقاله انگلیسی:
VI. CONCLUSIONS & FUTURE WORK
In this work, we introduce a dissimilarity feature extraction framework through which we augment items’ representations with new features. When utilized in classification tasks, these enriched representations are proved to be effective in discovering preferred items, since they result in an improved performance in terms of precision. Presented results from the applied classifiers and the feature selection techniques endorse the usability of our features.
In future work, we are interested in comparing our features with state-of-the-art research efforts such as matrix factorization techniques [17]. Such comparison studies will greatly enhance the importance of our work. Furthermore, considering the computational complexity of our feature extraction framework, we plan to provide a distributed implementation through which its execution time will be reduced. Finally, the proposed framework could be adjusted in order to provide suggestions in the context of social networks. Considering a community of users, we could calculate dissimilarity features for the items they have expressed their opinion. Then, these features could lead to dissimilarities between users which can be used for their separation into two poles. The one pole would contain the users with small pairwise dissimilarity weights (i.e. like-minded users), while the other pole would include the ones with high dissimilarity weights (i.e. opposite-minded user). Applications that seek a balance between accuracy and diversity could use both poles of users.
|
تصویری از مقاله ترجمه و تایپ شده در نرم افزار ورد |
|
|
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی
|
|
| عنوان فارسی مقاله: |
خصوصیات عدم تجانس در سیستم های توصیه کننده |
| عنوان انگلیسی مقاله: |
Dissimilarity Features in Recommender Systems |
|
|