گروه آموزشی ترجمه فا اقدام به ارائه ترجمه مقاله با موضوع ” الگوریتم تکاملی ترکیبی جهت انتخاب صفت در دیتاماینینگ ” در قالب فایل ورد نموده است که شما عزیزان میتوانید پس از دانلود رایگان مقاله انگلیسی و نیز مطالعه نمونه ترجمه و سایر مشخصات، ترجمه را خریداری نمایید.
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی
|
|
| عنوان فارسی مقاله: |
یک الگوریتم تکاملی هیبریدی برای انتخاب ویژگی در داده کاوی |
| عنوان انگلیسی مقاله: |
A hybrid evolutionary algorithm for attribute selection in data mining |
|
|
| مشخصات مقاله انگلیسی (PDF) | |
| سال انتشار | 2009 |
| تعداد صفحات مقاله انگلیسی | 15 صفحه با فرمت pdf |
| رشته های مرتبط با این مقاله | مهندسی کامپیوتر |
| گرایش های مرتبط با این مقاله | هوش مصنوعی و مهندسی الگوریتم ها و محاسبات |
| مجله | سیستم های خبره با کاربردهای آن – Expert Systems with Applications |
| دانشگاه | گروه مهندسی برق و کامپیوتر، دانشگاه ملی سنگاپور |
| کلمات کلیدی | الگوریتم های تکاملی، ماشین های بردار پشتیبانی، داده کاوی، انتخاب ویژگی، طبقه بندی الگو |
| شناسه شاپا یا ISSN | ISSN 2008.10.013 |
| رفرنس | دارد |
| لینک مقاله در سایت مرجع | لینک این مقاله در نشریه Elsevier |
| نشریه | Elsevier |
| مشخصات و وضعیت ترجمه فارسی این مقاله (Word) | |
| تعداد صفحات ترجمه تایپ شده با فرمت ورد با قابلیت ویرایش و فونت 14 B Nazanin | 34 صفحه |
| ترجمه عناوین تصاویر و جداول | ترجمه شده است |
| ترجمه متون داخل تصاویر | ترجمه نشده است |
| ترجمه متون داخل جداول | ترجمه نشده است |
| درج تصاویر در فایل ترجمه | درج شده است |
| درج جداول در فایل ترجمه | درج شده است |
| درج فرمولها و محاسبات در فایل ترجمه به صورت عکس | درج شده است |
- فهرست مطالب:
چکیده
1. مقدمه
2. انتخاب ویژگی در داده کاوی
2.1. انتخاب ویژگی
2.2. لفاف در مقابل رویکرد فیلتر
3.GA-SVM هیبرید
3.1. الگوریتم ژنتیک(GA)
3.2. جمعیت و ساختار کروموزوم
3.3 عملگرهای ژنتیکی
3.4 ماشین های بردار پشتیبانی (SVM)
3.5. گردش کار هیبرید GA-SVM
4. مطالعه موردی
4.1. راه اندازی تجربی
4.2. مجموعه داده های انتخاب شده
4.3 نتایج و تجزیه و تحلیل شبیه سازی
4.3.1 برابری با SVM خالص
4.3.2. برابری با سایر آثار
فیشرهای مجموعه داده های Iris
مجموعه داده های دیابت
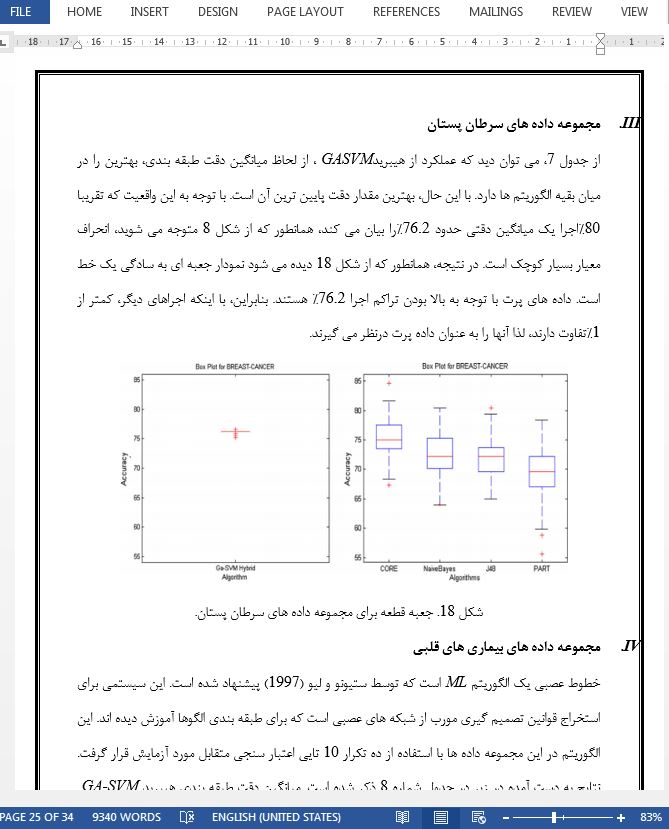
مجموعه داده های سرطان پستان
مجموعه داده های بیماری های قلبی
مجموعه داده های هپاتیت
4.3.3. بحث و خلاصه بندی
5. بهسازی هیبرید Ga-Svm
1.5 بهسازی مبتنی بر همبستگی
(الف) روش
(ب) نتایج و بحث
بهسازی مبتنی بر پارامتر
6. نتیجه گیری
- بخشی از ترجمه:
6. نتیجه گیری
در این مقاله یک الگوریتم تکاملی هیبریدی برای انتخاب ویژگی در داده کاوی پیشنهاد شد. هیبرید GA-SVM با ماهیت تصادفی از الگوریتم های ژنتیکی با هم با توانایی گسترده ای از ماشین بردار پشتیبانی در جستجو برای یک مجموعه مطلوب از ویژگی ها ترکیب می شوند. رفع ویژگی های حشو مورد استفاده هیبرید GA-SVM کیفیت مجموعه داده ها را بهبود می بخشد و امکان طبقه بندی بهتر اطلاعات نهان را در آینده. به وجود می آورد. هیبرید GA-SVM پیشنهادی بر 5 مجموعه داده های به دست آمده از مخزن یادگیری دستگاهمور UCI مورد تایید قرار گرفت. نتایج جمع آوری شده نشان داده اند که هیبرید پیشنهادی قادر به تولید میانگین دقت طبقه بندی بالایی است که قابل مقایسه و یا بهتر از برخی از طبقه بندی کنندگان منتشر شده در جامعه داده کاوی هستند. شبیه سازی ویترین ثبات آماری هیبرید GA-SVM را انجام می دهد، که از تجزیه و تحلیل هیستوگرام ها و نمودارهای جعبه ای آشکار هستند. بهسازی ثانویه هیبرید شامل استفاده از اندازه همبستگی جهت بهبود میانگین سلامتی در یک جمعیت کروموزومی است. نتایج به دست آمده بازبینی شدند که جانشینی کروموزوم های ضعیف تر بر اساس اندازه همبستگی قابلیت طبقه بندی هیبرید را بهبود می بخشد. این موضوع از دقت بالاتر طبقه بندی به دست آمده پس از آزمایش در همان مجموعه داده UCI مشاهده شد. ثبات طبقه بندی کننده نیز به عنوان تعیین با واریانس کم از نتایج جمع آوری شده افزایش می یابد. بنابراین تجزیه و تحلیل ها تا به اینجا زیست پذیری هیبرید GA-SVM به عنوان یک طبقه بندی خوب را تا زمانی که ویژگی های بی ربط حذف می شوند، اثبات می کنند.
- بخشی از مقاله انگلیسی:
6. Conclusions
This paper has proposed a hybrid evolutionary algorithm for attribute selection in data mining. The GA-SVM hybrid incorporates the stochastic nature of genetic algorithms together with the vast capability of support vector machines in the search for an optimal set of attributes. The eradication of the redundant attributes using the GA-SVM hybrid improves the quality of the data sets and enables better classification of future unseen data. The proposed GA-SVM hybrid was validated upon 5 data sets obtained from UCI machine learning repository. Results collated have shown that the proposed hybrid is able to produce a high average classification accuracy that is comparable or better than some of the established classifiers in the data mining community. The simulations carried out also showcase the statistical consistency of the GA-SVM hybrid, which is evident from the histogram analysis and box plots. Secondary improvements to the hybrid included the utilization of a correlation measure to improve the average fitness of a chromosome population. The results obtained verify that the substitution of weaker chromosomes based on the correlation measure improved the hybrid’s classification ability. This was observed from the higher classification accuracy attained upon testing on the same UCI data sets. The stability of the classifier was also enhanced as ascertained by the low variance of the results collected. The analysis hitherto has thus demonstrated the viability of the GA-SVM hybrid as a good classifier when the irrelevant attributes are removed.6. Conclusions This paper has proposed a hybrid evolutionary algorithm for attribute selection in data mining. The GA-SVM hybrid incorporates the stochastic nature of genetic algorithms together with the vast capability of support vector machines in the search for an optimal set of attributes. The eradication of the redundant attributes using the GA-SVM hybrid improves the quality of the data sets and enables better classification of future unseen data. The proposed GA-SVM hybrid was validated upon 5 data sets obtained from UCI machine learning repository. Results collated have shown that the proposed hybrid is able to produce a high average classification accuracy that is comparable or better than some of the established classifiers in the data mining community. The simulations carried out also showcase the statistical consistency of the GA-SVM hybrid, which is evident from the histogram analysis and box plots. Secondary improvements to the hybrid included the utilization of a correlation measure to improve the average fitness of a chromosome population. The results obtained verify that the substitution of weaker chromosomes based on the correlation measure improved the hybrid’s classification ability. This was observed from the higher classification accuracy attained upon testing on the same UCI data sets. The stability of the classifier was also enhanced as ascertained by the low variance of the results collected. The analysis hitherto has thus demonstrated the viability of the GA-SVM hybrid as a good classifier when the irrelevant attributes are removed.6. Conclusions This paper has proposed a hybrid evolutionary algorithm for attribute selection in data mining. The GA-SVM hybrid incorporates the stochastic nature of genetic algorithms together with the vast capability of support vector machines in the search for an optimal set of attributes. The eradication of the redundant attributes using the GA-SVM hybrid improves the quality of the data sets and enables better classification of future unseen data. The proposed GA-SVM hybrid was validated upon 5 data sets obtained from UCI machine learning repository. Results collated have shown that the proposed hybrid is able to produce a high average classification accuracy that is comparable or better than some of the established classifiers in the data mining community. The simulations carried out also showcase the statistical consistency of the GA-SVM hybrid, which is evident from the histogram analysis and box plots. Secondary improvements to the hybrid included the utilization of a correlation measure to improve the average fitness of a chromosome population. The results obtained verify that the substitution of weaker chromosomes based on the correlation measure improved the hybrid’s classification ability. This was observed from the higher classification accuracy attained upon testing on the same UCI data sets. The stability of the classifier was also enhanced as ascertained by the low variance of the results collected. The analysis hitherto has thus demonstrated the viability of the GA-SVM hybrid as a good classifier when the irrelevant attributes are removed.
|
تصویری از مقاله ترجمه و تایپ شده در نرم افزار ورد |
|
|
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی
|
|
| عنوان فارسی مقاله: |
الگوریتم تکاملی ترکیبی جهت انتخاب صفت در دیتاماینینگ |
| عنوان انگلیسی مقاله: |
A hybrid evolutionary algorithm for attribute selection in data mining |
|
|