این مقاله انگلیسی ISI در نشریه اسپرینگر در 18 صفحه در سال 2016 منتشر شده و ترجمه آن 36 صفحه میباشد. کیفیت ترجمه این مقاله ویژه – طلایی ⭐️⭐️⭐️ بوده و به صورت کامل ترجمه شده است.
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی | |
| عنوان فارسی مقاله: |
مطالعه تجربی درباره برخی تکنیک های پیش بینی خطای نرم افزار به منظور تعداد پیش بینی خطاها |
| عنوان انگلیسی مقاله: |
An empirical study of some software fault prediction techniques for the number of faults prediction |
|
|
|
| مشخصات مقاله انگلیسی | |
| فرمت مقاله انگلیسی | |
| سال انتشار | 2016 |
| تعداد صفحات مقاله انگلیسی | 18 صفحه با فرمت pdf |
| نوع مقاله | ISI |
| نوع ارائه مقاله | ژورنال |
| رشته های مرتبط با این مقاله | مهندسی کامپیوتر |
| گرایش های مرتبط با این مقاله | مهندسی نرم افزار، طراحی و تولید نرم افزار |
| چاپ شده در مجله (ژورنال) | محاسبات نرم – Soft Computing |
| کلمات کلیدی | پیش بینی خطای نرم افزار، رگرسیون پوآسون بدون تورم، برنامه نویسی ژنتیک، پرسپترون چند لایه، تست Kruskal–Wallis، تست مقایسه چندگانه Dunn |
| کلمات کلیدی انگلیسی | Software fault prediction – Zero-inflated Poisson regression – Genetic programming – Multilayer perceptron – Kruskal–Wallis test – Dunn’s multiple comparison test |
| ارائه شده از دانشگاه | گروه علوم و مهندسی کامپیوتر، موسسه فناوری هند روکی، هند |
| نمایه (index) | scopus – master journals – JCR – Master ISC |
| نویسندگان | Santosh S. Rathore – Sandeep Kumar |
| شناسه شاپا یا ISSN | 1432-7643 |
| شناسه دیجیتال – doi | https://doi.org/10.1007/s00500-016-2284-x |
| ایمپکت فاکتور(IF) مجله | 3.864 در سال 2020 |
| شاخص H_index مجله | 81 در سال 2021 |
| شاخص SJR مجله | 0.626 در سال 2020 |
| شاخص Q یا Quartile (چارک) | Q2 در سال 2020 |
| بیس | نیست ☓ |
| مدل مفهومی | ندارد ☓ |
| پرسشنامه | ندارد ☓ |
| متغیر | ندارد ☓ |
| فرضیه | ندارد ☓ |
| رفرنس | دارای رفرنس در داخل متن و انتهای مقاله ✓ |
| کد محصول | 12294 |
| لینک مقاله در سایت مرجع | لینک این مقاله در سایت Springer |
| نشریه | اسپرینگر – Springer |
| مشخصات و وضعیت ترجمه فارسی این مقاله | |
| فرمت ترجمه مقاله | pdf و ورد تایپ شده با قابلیت ویرایش |
| وضعیت ترجمه | انجام شده و آماده دانلود |
| کیفیت ترجمه | ویژه – طلایی ⭐️⭐️⭐️ |
| تعداد صفحات ترجمه تایپ شده با فرمت ورد با قابلیت ویرایش | 36 (2 صفحه رفرنس انگلیسی) صفحه با فونت 14 B Nazanin |
| ترجمه عناوین تصاویر و جداول | ترجمه شده است ✓ |
| ترجمه متون داخل تصاویر | ترجمه شده است ✓ |
| ترجمه متون داخل جداول | ترجمه شده است ✓ |
| ترجمه ضمیمه | ندارد ☓ |
| ترجمه پاورقی | ندارد ☓ |
| درج تصاویر در فایل ترجمه | درج شده است ✓ |
| درج جداول در فایل ترجمه | درج شده است ✓ |
| درج فرمولها و محاسبات در فایل ترجمه | به صورت عکس درج شده است ✓ |
| منابع داخل متن | به صورت انگلیسی درج شده است ✓ |
| منابع انتهای متن | به صورت انگلیسی درج شده است ✓ |
| فهرست مطالب |
|
چکیده 1. مقدمه 2. کار مرتبط 3. تکنیک های پیش بینی خطا 3-1 مدل های شمارش 3-1-1 رگرسیون دو جمله ای منفی 3-1-2 رگرسیون پوآسون با تورم صفر 3-2 دیگر تکنیک های پیش بینی خطا 3-2-2 پرسپترون چند لایه 3-2-3 برنامه نویسی ژنتیک 3-2-4 رگرسیون درخت تصمیم 3-3 معیارهای ارزیابی عملکرد 4. مطالعه موردی تجربی 4-1 توصیف سیستم 4-2 طراحی تجربی 4-3 نتایج و تحلیل 4-3-1 تحلیل AAE و ARE 4-3-2 معیار کامل بودن 4-3-3 پیش بینی در تحلیل سطح 1 4-4 معیارهای مهم برای پیش بینی تعداد خطاها 5. تحلیل مقایسه ای 6. تهدیدات به اعتبار 7. نتیجه گیری ها و کار آتی منابع |
| بخشی از ترجمه |
|
چکیده در طی فرآیند توسعه نرم افزار، پیش بینی تعداد خطاها در ماژول های نرم افزاری می تواند بسیار کمک کننده تر از پیش بینی ماژول هایی باشد که دچار خطا شده اند یا بدون خطا هستند. چنین روشی می تواند در فرآیند تست نرم افزار کمک کند و سبب ارتقاء قابلیت اطمینان سیستم نرم افزار شود. بیشتر کارهای اولیه درباره پیش بینی خطای نرم افزار از تکنیک های دسته بندی برای طبقه بندی ماژول های نرم افزاری به گروه های خطادار یا بدون خطا استفاده کرده اند. این تکنیک ها همانند رگرسیون پوآسون، رگرسیون دو جمله ای منفی ، برنامه نویسی ژنتیک، رگرسیون درخت تصمیم و پرسپترون چند لایه در پیش بینی تعداد خطاها قابل استفاده هستند. در این مقاله یک مطالعه تجربی برای ارزیابی و مقایسه ظرفیت شش تکنیک پیش بینی خطا از جمله برنامه نویسی ژنتیک، پرسپترون چند لایه، رگرسیون خطی، رگرسیون درخت تصمیم، رگرسیون پوآسون و رگرسیون دو جمله ای منفی را به منظور پیش بینی تعداد خطاها ارائه می کنیم. این بررسی تجربی برای 18 دیتاست پروژه نرم افزاری انجام شده است که از مخزن داده های PROMISE جمع آوری شده است. نتایج این تحقیق با استفاده از متوسط خطای مطلق، متوسط خطای نسبی، اندازه گیری میزان کامل بودن و پیش بینی در معیارهای سطح 1 مورد ارزیابی قرار گرفته اند. همچنین تست های Kruskal–Wallis و مقایسه چندتایی Dunn را برای مقایسه عملکرد نسبی تکنیک های پیش بینی خطا انجام می دهیم.
1. مقدمه از دیدگاه توسعه نرم افزار، سر و کار داشتن با خطاهای نرم افزاری کاری بسیار مهم و از اولویت بالایی برخوردار است. وجود خطاها نه تنها سبب افت کیفیت نرم افزار می شود، بلکه همچنین هزینه توسعه و نگهداری نرم افزار را نیز افزایش می دهد (Menzies et al. 2010). بنابراین شناسایی این که کدام ماژول نرم افزار با احتمال زیاد در طی مراحل اولیه توسعه نرم افزار می تواند مستعد خطا باشد، می تواند در بهبود کیفیت سیستم نرم افزار کمک کننده باشد. با پیش بینی تعداد خطاها در ماژول های نرم افزار می توانیم تست کننده های نرم افزار را برای تمرکز بر ماژول های خطادار هدایت کنیم.
7. نتیجه گیری ها و کار آتی این مقاله عملکرد شش تکنیک پیش بینی خطا را برای پیش بینی تعداد خطاها در ماژول های نرم افزاری داده شده مورد بررسی و مقایسه قرار داده است. ما از چهار تکنیک شناخته شده پیش بینی خطا یعنی LR، MLP، NBR و ZIP برای پیش بینی تعداد خطاها استفاده کرده ایم. علاوه بر این، ما دو تکنیک یعنی GP و DTR را نیز مورد بررسی قرار داده ایم که تا به حال به طور کامل برای پیش بینی تعداد خطاها مورد بررسی قرار نگرفته اند. این آزمایش ها برای 18 دیتاست پروژه نرم افزاری اجرا شده است. معیارهای AAE، ARE، کامل بودن و پیش بینی در سطح 1 برای ارزیابی نتایج حاصل از مدل های پیش بینی خطا مورد استفاده قرار گرفته اند. علاوه بر این، تست Kruskal–Wallis و تست مقایسه چندگانه Dunn نیز برای ارزیابی عملکرد نسبی تکنیک های پیش بینی خطا اجرا شده است. نتایج نشان داده است که در بین تکنیک های مختلف پیش بینی خطا، روش های رگرسیون درخت تصمیم، برنامه نویسی ژنتیک، پرسپترون چند لایه و رگرسیون خطی عملکرد پیش بینی بهتری برای تمامی دیتاست های تحت بررسی نشان داده اند. تحلیل نتایج به دست آمده از تست Kruskal–Wallis و تست مقایسه چندگانه Dunn پیشنهاد داده اند که به استثنای تکنیک های رگرسیون دوجمله ای منفی (NBR) و رگرسیون پوآسون با تورم صفر (ZIP)، تمامی تکنیک های دیگر عملکرد بسیار دقیقی برای پیش بینی تعداد خطاها داشته اند. به طور کلی، تکنیک های NBR و ZIP بدترین دقت پیش بینی را تولید کرده اند. بنابراین، مشاهده می شود که مدل های شمارش (NBR و ZIP) به طور کلی عملکرد ضعیفی نسبت به دیگر تکنیک های پیش بینی خطا داشته اند. در آینده سعی می شود تا اثر کلی این روش ها برای تعداد پیش بینی خطاها به منظور غلبه بر محدودیت های تکنیک های پیش بینی خطا مورد بررسی و ارزیابی قرار گیرد. |
| بخشی از مقاله انگلیسی |
|
Abstract During the software development process, prediction of the number of faults in software modules can be more helpful instead of predicting the modules being faulty or non-faulty. Such an approach may help in more focused software testing process and may enhance the reliability of the software system. Most of the earlier works on software fault prediction have used classification techniques for classifying software modules into faulty or non-faulty categories. The techniques such as Poisson regression, negative binomial regression, genetic programming, decision tree regression, and multilayer perceptron can be used for the prediction of the number of faults. In this paper, we present an experimental study to evaluate and compare the capability of six fault prediction techniques such as genetic programming, multilayer perceptron, linear regression, decision tree regression, zero-inflated Poisson regression, and negative binomial regression for the prediction of number of faults. The experimental investigation is carried out for eighteen software project datasets collected from the PROMISE data repository. The results of the investigation are evaluated using average absolute error, average relative error, measure of completeness, and prediction at level l measures. We also perform Kruskal–Wallis test and Dunn’s multiple comparison test to compare the relative performance of the considered fault prediction techniques.
1 Introduction From software development perspective, dealing with software faults is a vital and foremost important task. Presence of faults not only deteriorates the quality of the software, but also increases the development and maintenance cost of the software (Menzies et al. 2010). Therefore, identifying which software module is likely to be fault prone during early phases of software development may help in improving the quality of software system. By predicting number of faults1 in software modules, we can guide software testers to focus on faulty modules first.
7 Conclusions and future work This paper evaluated and compared the performance of six fault prediction techniques for the prediction of number of faults in given software modules. We have used four known fault prediction techniques, i.e., LR, MLP, NBR, and ZIP for the prediction of number of faults. In addition, we have investigated two techniques, i.e., GP and DTR, which until now have not been fully explored for the prediction of number of faults. The experiments were performed for eighteen software project datasets available publicly. AAE, ARE, measure of completeness, and prediction at level l measures have been used to evaluate the results of fault prediction models. In addition, Kruskal–Wallis test and Dunn’s multiple comparison test were performed to assess the relative performance of the used fault prediction techniques. The results found that among the used different fault prediction techniques, decision tree regression, genetic programming, multilayer perceptron, and linear regression demonstrated better prediction performance for all the datasets under consideration. The analysis of results obtained from Kruskal–Wallis test and Dunn’s multiple comparison test suggested that except negative binomial regression (NBR) and zero-inflated Poisson regression (ZIP) techniques all other techniques have performed significantly accurate for the prediction of number of faults. Generally, NBR and ZIP techniques produced the worst prediction accuracy. Thus, it is observed that the count models (NBR and ZIP) generally underperformed as compared to other considered fault prediction techniques. In the future, it may be tried to investigate and evaluate ensemble of these methods for the number of faults prediction to overcome the limitations of individual techniques. |
|
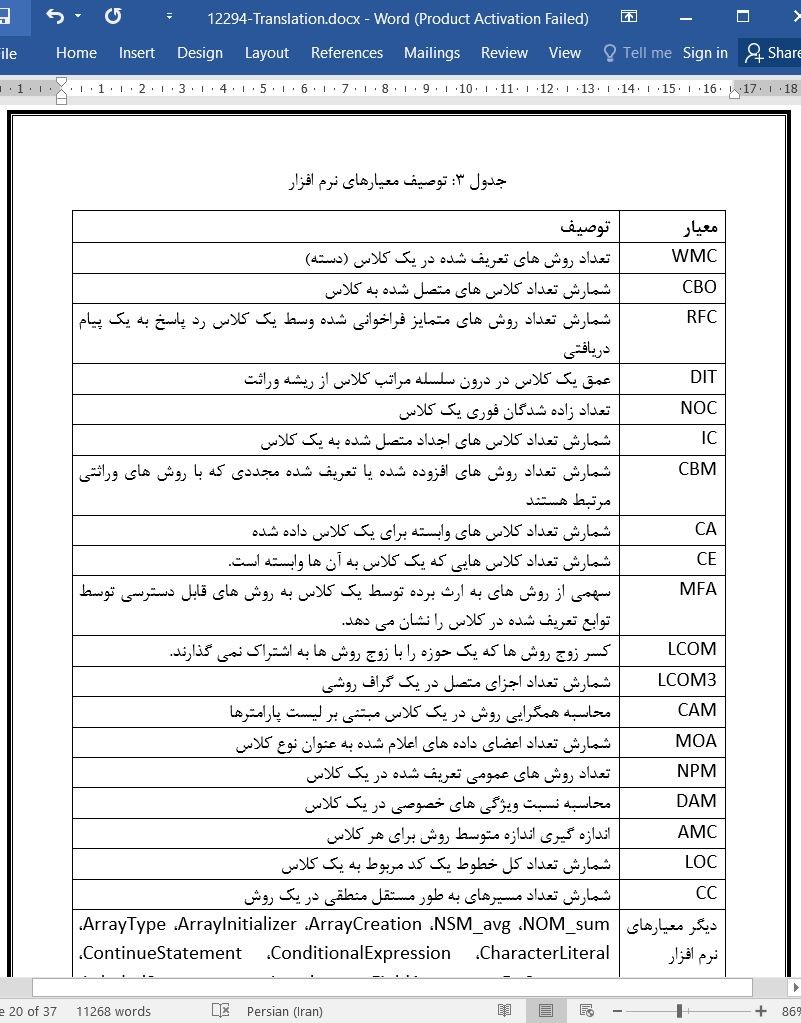
تصویری از مقاله ترجمه و تایپ شده در نرم افزار ورد |
|
|
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی | |
| عنوان فارسی مقاله: |
مطالعه تجربی درباره برخی تکنیک های پیش بینی خطای نرم افزار به منظور تعداد پیش بینی خطاها |
| عنوان انگلیسی مقاله: |
An empirical study of some software fault prediction techniques for the number of faults prediction |
|
|
|