این مقاله انگلیسی ISI در نشریه الزویر در 11 صفحه در سال 2021 منتشر شده و ترجمه آن 30 صفحه میباشد. کیفیت ترجمه این مقاله ویژه – طلایی ⭐️⭐️⭐️ بوده و به صورت کامل ترجمه شده است.
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی | |
| عنوان فارسی مقاله: |
یادگیری شمارش دقیق و برآورد تقریبی در مدل های شبکه عصبی عمیق |
| عنوان انگلیسی مقاله: |
Learning exact enumeration and approximate estimation in deep neural network models |
|
|
|
| مشخصات مقاله انگلیسی | |
| فرمت مقاله انگلیسی | pdf و ورد تایپ شده با قابلیت ویرایش |
| سال انتشار | 2021 |
| تعداد صفحات مقاله انگلیسی | 11صفحه با فرمت pdf |
| نوع مقاله | ISI |
| نوع نگارش | مقاله پژوهشی (Research Article) |
| نوع ارائه مقاله | ژورنال |
| رشته های مرتبط با این مقاله | مهندسی کامپیوتر |
| گرایش های مرتبط با این مقاله | هوش مصنوعی، مهندسی الگوریتم ها و محاسبات |
| چاپ شده در مجله (ژورنال) | شناخت – Cognition |
| کلمات کلیدی | درک اعداد، اعداد تقریبی، اعداد دقیق، شبکه های عصبی عمیق، مدلسازی مفهومی، بازنمایی ها |
| کلمات کلیدی انگلیسی | Number sense – Approximate number – Exact number – Deep neural networks – Computational modelling – Representations |
| ارائه شده از دانشگاه | گروه آموزش معلمان، دانشکده علوم اجتماعی و تربیتی ، دانشگاه علم و صنعت نروژ |
| نمایه (index) | Medline – Scopus – Master Journal List – JCR |
| نویسندگان | Celestino Creatore , Silvester Sabathiel , Trygve Solstad |
| شناسه شاپا یا ISSN | 0010-0277 |
| شناسه دیجیتال – doi | https://doi.org/10.1016/j.cognition.2021.104815 |
| ایمپکت فاکتور(IF) مجله | 3.549 در سال 2020 |
| شاخص H_index مجله | 187 در سال 2021 |
| شاخص SJR مجله | 2.080 در سال 2020 |
| شاخص Q یا Quartile (چارک) | Q1 در سال 2020 |
| بیس | نیست ☓ |
| مدل مفهومی | ندارد ☓ |
| پرسشنامه | ندارد ☓ |
| متغیر | ندارد ☓ |
| فرضیه | ندارد ☓ |
| رفرنس | دارای رفرنس در داخل متن و انتهای مقاله ✓ |
| کد محصول | 12059 |
| لینک مقاله در سایت مرجع | لینک این مقاله در سایت Elzevier |
| نشریه | الزویر – Elsevier |
| مشخصات و وضعیت ترجمه فارسی این مقاله | |
| فرمت ترجمه مقاله | pdf و ورد تایپ شده با قابلیت ویرایش |
| وضعیت ترجمه | انجام شده و آماده دانلود |
| کیفیت ترجمه | ویژه – طلایی ⭐️⭐️⭐️ |
| تعداد صفحات ترجمه تایپ شده با فرمت ورد با قابلیت ویرایش | 30 صفحه با فونت 14 B Nazanin |
| ترجمه عناوین تصاویر و جداول | ترجمه شده است ✓ |
| ترجمه متون داخل تصاویر | ترجمه شده است ✓ |
| ترجمه متون داخل جداول | ترجمه شده است ✓ |
| ترجمه ضمیمه | ندارد ☓ |
| درج تصاویر در فایل ترجمه | درج شده است ✓ |
| درج جداول در فایل ترجمه | درج شده است ✓ |
| درج فرمولها و محاسبات در فایل ترجمه | تایپ شده است✓ |
| منابع داخل متن | ترجمه شده است ✓ |
| منابع انتهای متن | ترجمه شده است ✓ |
ترجمه شده است ✓
| فهرست مطالب |
|
چکیده ۱. مقدمه ۲. روش ها ۳. نتایج ۴. بحث منابع |
| بخشی از ترجمه |
|
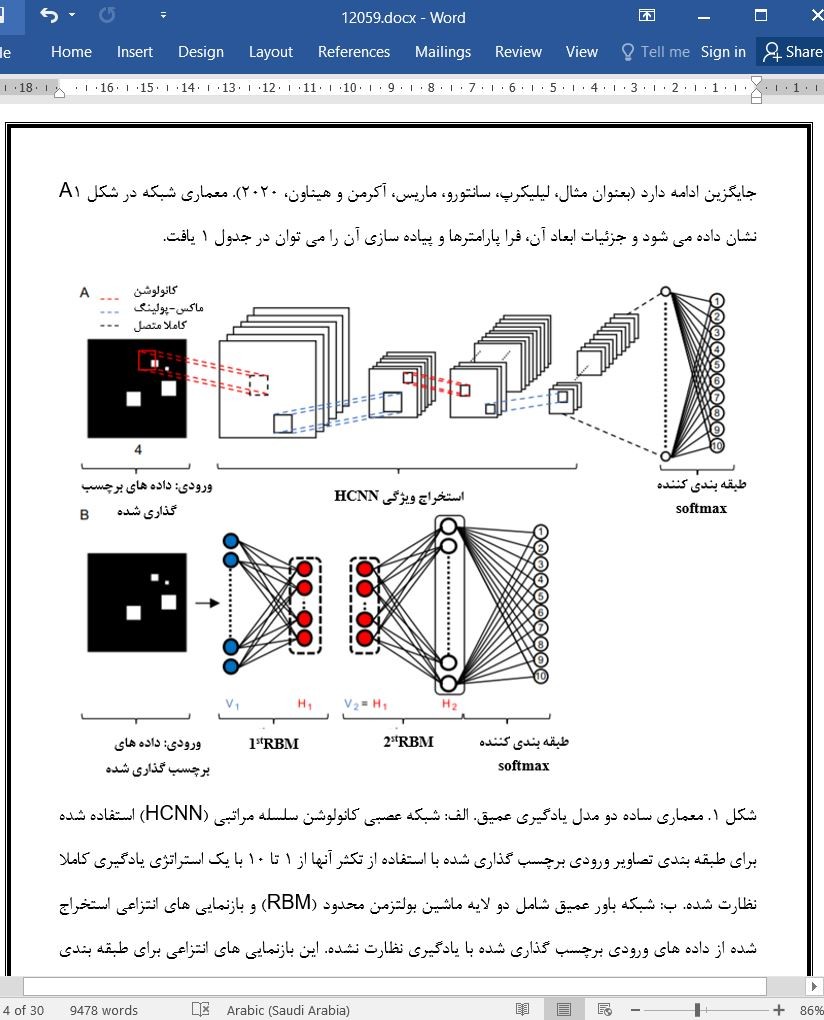
چکیده یک سیستم برای تفکیک پذیری اعداد تقریبی نشان داده شده است تا حداقل در دو نوع مدل شبکه عصبی سلسله مراتبی- یک شبکه باور عمیق مولد (DBN) بوجود آید و یک شبکه عصبی کانولوشن سلسله مراتبی (HCNN) برای طبقه بندی آبجکت های طبیعی آموزش داده شود. در اینجا، این موضوع را بررسی می کنیم که آیا دو معماری شبکه مشابه می توانند درباره تشخیص دقیق تکثر بیاموزند یا خیر. تفاوت واضح در عملکرد را می توان برای اختصاصی کردن پاسخ های واحد که در آخرین لایه پنهان هر شبکه ظاهر می شوند، پیگیری کرد. در DBN، ظهور یک لایه از واحدهای مجموع یکنوا، برای ایجاد رفتار طبقه بندی سازگار با امضای رفتاری سیستم عدد تقریبی کافی بود. در HCNN، لایه ای از واحدها که به صورت منحصربفردی برای انتقال بین اعداد خاص تنظیم شده اند، یک کد تکثر شبیه دماسنج را یه صورت موثری رمزگذاری می کنند که دقت طبقه بندی تقریبا کامل را تضمین می کند. نتایج نشان می دهند که مکانیسم های تشخیص الگوی موازی ممکن است مفاهیم اعداد تقریبی و دقیق را ایجاد کنند، هر کدام از آنها ممکن است که به یادگیری اعداد و حساب نمادین کمک کنند. ۱. مقدمه مبنای توسعه مفهومی اعداد طبیعی و حساب مقدماتی چیست؟ اگرچه، شمارش تنها روش دقیق ما برای تعیین اندازه مجموعه بزرگی از آیتم ها است، انسان ها و حیوانات درک عددی طبیعی دارند که شامل دو مولفه می شود؛ ما برای مجموعه های کوچکتر از پنج می توانیم تعداد دقیق آیتم ها را در یک فرایند با نام «سابتایزینگ» درک کنیم (آگریلو،پیفر، بیسازا، و باترورث، ۲۰۱۲؛ کلمنتس، ساراما، و مک دونالد، ۲۰۱۹؛ جوونز، ۱۸۷۱، توموناگا، و ماتسوزاوا، ۲۰۰۲). فراتر از این محدوده سابتایزینگ می توانیم قضاوت های تقریبی ایجاد کنیم، درباره (۱) تکثر یک مجموعه واحد از آیتم ها (وظیفه برآورد)، و (۲) اندازه نسبی دو مجموعه از آیتم ها (وظیفه جداسازی) با دقتی که به صورت لگاریتمی با اندازه مجموعه یا تفاضل بین مجموعه ها کاهش می یابد (دهائن، ۲۰۱۱؛ ایزارد، سان، اسپلک، استرری، ۲۰۰۹؛ روگانی، رگولین، و والورتیگارا، ۲۰۰۸). درک این موضوع که چگونه ادراک تقریبی اعداد ممکن است در درک مبنا قرار گیرد، از طریق آزمایشات فیزیولوژی عصبی و مدلسازی مفهومی پیشرفت کرده است (نیئدر و دهائن، ۲۰۰۹). با این حال، اینکه چه مکانیسم های شناختی زمینه ساز می شوند و براورد تقریبی و شمارش دقیق را متمایز می کنند، هنوز مبهم است. ۴. بحث ما در این مقاله این موضوع را بررسی کردیم که آیا و چگونه یادگیری اعداد کوچک نمادین را میتوان با استفاده از اصول یادگیری کلی شبکه های عصبی سلسله مراتبی پشتیبانی کرد. ما دو شبکه از معماری های مختلف و الگوریتم های یادگیری را آموزش دادیم تا مجموعه داده های ورودی مشابه تصاویر الگو-نقطه را با استفاده از طبقه بندی کننده خروجی یکسان دسته بندی کنیم. |
| بخشی از مقاله انگلیسی |
|
Abstract A system for approximate number discrimination has been shown to arise in at least two types of hierarchical neural network models—a generative Deep Belief Network (DBN) and a Hierarchical Convolutional Neural Network (HCNN) trained to classify natural objects. Here, we investigate whether the same two network architectures can learn to recognise exact numerosity. A clear difference in performance could be traced to the specificity of the unit responses that emerged in the last hidden layer of each network. In the DBN, the emergence of a layer of monotonic ‘summation units’ was sufficient to produce classification behaviour consistent with the behavioural signature of the approximate number system. In the HCNN, a layer of units uniquely tuned to the transition between particular numerosities effectively encoded a thermometer-like ‘numerosity code’ that ensured near-perfect classification accuracy. The results support the notion that parallel pattern-recognition mechanisms may give rise to exact and approximate number concepts, both of which may contribute to the learning of symbolic numbers and arithmetic. 1. Introduction What is the foundation for the conceptual development of natural numbers and elementary arithmetic? Although counting is our only procedure for exactly determining the size of large sets of items, both humans and non-human animals have a natural ‘number sense’ that consists of two components; for sets smaller than five, we can directly perceive the exact number of items in a process called ‘subitizing’ (Agrillo, Piffer, Bisazza, & Butterworth, 2012; Clements, Sarama, & Macdonald, 2019; Jevons, 1871; Tomonaga & Matsuzawa, 2002). Beyond this ‘subitizing range’, we can make approximate judgements about (i) the numerosity of a single set of items (estimation task), and (ii) the relative size of two sets of items (discrimination task), with an accuracy that decreases logarithmically with the size of the set or the difference between sets (Dehaene, 2011; Izard, Sann, Spelke, & Streri, 2009; Rugani, Regolin, & Vallortigara, 2008). Recently, our understanding of how this approximate number sense may be grounded in perception has been substantially advanced through neurophysiological experiments and computational modelling (Nieder & Dehaene, 2009). However, what cognitive mechanisms underlie and differentiate approximate estimation and exact enumeration is still unclear. 4. Discussion In this paper we investigated if and how learning of small symbolic numbers can be supported by general learning principles of hierarchical neural networks. We trained two networks of different architectures and learning algorithms to classify the same input dataset of dot-pattern images using the same output classifier. |
|
تصویری از مقاله ترجمه و تایپ شده در نرم افزار ورد |
|
|
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی | |
| عنوان فارسی مقاله: |
یادگیری شمارش دقیق و برآورد تقریبی در مدل های شبکه عصبی عمیق |
| عنوان انگلیسی مقاله: |
Learning exact enumeration and approximate estimation in deep neural network models |
|
|
|