| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی | |
| عنوان فارسی مقاله: |
انتخاب ژن های مهم با استفاده از تست تصادفی برای رده بندی سرطان با داده های بیان ژن |
| عنوان انگلیسی مقاله: |
Selecting significant genes by randomization test for cancer classification using gene expression data |
|
|
|
| مشخصات مقاله انگلیسی (PDF) | |
| سال انتشار | 2013 |
| تعداد صفحات مقاله انگلیسی | 8 صفحه با فرمت pdf |
| نوع مقاله | ISI |
| نوع نگارش | مقاله پژوهشی (Research Article) |
| نوع ارائه مقاله | ژورنال |
| رشته های مرتبط با این مقاله | زیست شناسی و پزشکی |
| گرایش های مرتبط با این مقاله | ایمنی شناسی پزشکی، خون و آنکولوژی، بیوانفورماتیک و ژنتیک |
| چاپ شده در مجله (ژورنال) | مجله انفورماتیک زیست پزشکی – Journal of Biomedical Informatics |
| کلمات کلیدی | دسته بندی سرطان، داده های بیان ژن، آزمون تصادفی، آنالیز تفکیکی حداقل مربعات جزئی، انتخاب ژن |
| کلمات کلیدی انگلیسی | Gene expression data – Randomization test – Partial least squares discriminant analysis – Gene selection – Cancer classification |
| ارائه شده از دانشگاه | دانشکده شیمی، دانشگاه نانکای، چین |
| نمایه (index) | MedLine – Scopus – Master journals – JCR |
| نویسندگان | Zhiyi Mao، Wensheng Cai، Xueguang Shao |
| شناسه شاپا یا ISSN | ISSN 1532-0464 |
| شناسه دیجیتال – doi | https://doi.org/10.1016/j.jbi.2013.03.009 |
| ایمپکت فاکتور(IF) مجله | 3.571 در سال 2018 |
| شاخص H_index مجله | 83 در سال 2019 |
| شاخص SJR مجله | 1.023 در سال 2018 |
| شاخص Q یا Quartile (چارک) | Q1 در سال 2018 |
| بیس | است ✓ |
| مدل مفهومی | دارد ✓ |
| پرسشنامه | ندارد ☓ |
| متغیر | دارد ✓ |
| رفرنس | دارای رفرنس در داخل متن و انتهای مقاله ✓ |
| کد محصول | 9912 |
| لینک مقاله در سایت مرجع | لینک این مقاله در سایت الزویر |
| نشریه آی تریپل ای |  |
| مشخصات و وضعیت ترجمه فارسی این مقاله (Word) | |
| وضعیت ترجمه | انجام شده و آماده دانلود در فایل ورد و PDF |
| کیفیت ترجمه | طلایی⭐️ |
| تعداد صفحات ترجمه تایپ شده با فرمت ورد با قابلیت ویرایش | 21 صفحه (شامل 1 صفحه رفرنس انگلیسی) با فونت 14 B Nazanin |
| ترجمه عناوین تصاویر و جداول | ترجمه شده است ✓ |
| ترجمه متون داخل تصاویر | ترجمه شده است ✓ |
| ترجمه متون داخل جداول | ترجمه شده است ✓ |
| درج تصاویر در فایل ترجمه | درج شده است ✓ |
| درج جداول در فایل ترجمه | درج شده است ✓ |
| منابع داخل متن | به صورت عدد درج شده است ✓ |
| منابع انتهای متن | به صورت انگلیسی درج شده است ✓ |
| فهرست مطالب |
|
خلاصه 1- مقدمه 2- روش ها 2-1- روش آنالیز تفکیکی حداقل مربعات جزئی (PLSDA) 2-2- آزمون تصادفی 2-3- روش RT-PLSDA 3- مجموعه داده ها 4- نتایج و بحث 4-1- انتخاب ژن بر اساس آزمون تصادف 4-2- قابلیت اجرای روش RT-PLSDA 4-3- بررسی زیستی ژن های انتخاب شده 4-4- بررسی های بیشتر روی ژن های انتخاب شده 4-5- مقایسه اثر دسته بندی با ژن های انتخاب شده توسط روش های مختلف 5- نتیجه گیری منابع |
| بخشی از ترجمه |
|
چکیده انتخاب ژن مرحله اساسی در مطالعات بیوانفورماتیکی می باشد، چرا که این انتخاب ضامن طبقه بندی صحیح سرطان به دلیل ارتباط بسیار نزدیک آن با ژن هایی است که در این مسأله اختلال ایجاد می کنند. در این مطالعه از آزمون تصادفی (RT) برای انتخاب و دستیابی به داده¬های حاصل از بیان ژن آنها استفاده شده است. در این روش از یک روند آماری که بر گرفته شده از ضریب رگرسیون یک سری از مدل های PLSDA است برای بررسی قدرت ژن استفاده کرده¬اند. ژن های مورد اطمینان برای طبقه بندی داده¬های بدست آمده از بیان ژن 4 نوع سرطان پروستات، ریه، لوسمی و NSCLC انتخاب شده و صحت نسبت بین نتایج از طریق مدل سازی رگرسیون خطی (MLR) و آنالیز ترکیبی پیش بالینی (PCA) مورد تأیید قرار گرفت. با ژن های انتخاب شده نتایج رضایتمندی می تواند حاصل شود.
5- نتیجه گیری تست تصادفی سازی به عنوان روشی برای انتخاب ژن به کار برده شد. این روش می تواند مهم بودن یک ژن را با استفاده از داده های آماری ضریب رگراسیون در یک سری از مدل های PLSDA بدست آورد. بنابراین برخی از ژن های مهم می تواند از بین هزاران ژن یا بیشتر در داده بیانی انتخاب شود. با تکرار محاسبات، فراوانی یک ژن می تواند به عنوان معیاری برای بررسی معنادار بودن آن استفاده شود. چهار مجموعه داده سرطان پروستات، سرطان ریه، لوسمی و NSCLC با استفاده از این روش مورد بررسی قرار گرفته اند. به ترتیب 18، 4، 9 و 7 ژن مهم شناسایی شده و منطق نتایج با مدل سازی MLR و PCA تایید شد. در مقایسه با نتایج بدست آمده از مطالعات قبلی، برتری این روش اثبات شده است. بنابراین این روش ممکن است ابزار جایگزینی برای دسته بندی با استفاده از داده های بیان باشد. |
| بخشی از مقاله انگلیسی |
|
Abstract Gene selection is an important task in bioinformatics studies, because the accuracy of cancer classification generally depends upon the genes that have biological relevance to the classifying problems. In this work, randomization test (RT) is used as a gene selection method for dealing with gene expression data. In the method, a statistic derived from the statistics of the regression coefficients in a series of partial least squares discriminant analysis (PLSDA) models is used to evaluate the significance of the genes. Informative genes are selected for classifying the four gene expression datasets of prostate cancer, lung cancer, leukemia and non-small cell lung cancer (NSCLC) and the rationality of the results is validated by multiple linear regression (MLR) modeling and principal component analysis (PCA). With the selected genes, satisfactory results can be obtained.
5- Conclusions Randomization test is employed as a gene selection method. The method can evaluate the significance of a gene by a statistic of the regression coefficients in a series of random PLSDA models. Therefore, a few of the significant genes can be selected from the thousands or more genes in an expression data. With repetition of the calculations, the frequency number of a gene can be further used as a criterion to evaluate its significance. Four datasets of prostate cancer dataset, lung cancer dataset, leukemia dataset and NSCLC dataset are investigated by the method. 18, 4, 9 and 7 significant genes are identified, respectively, and the rationality of the results is validated by MLR modeling and PCA. Compared with the results obtained in previous studies, the superiority of the method is proved. Therefore, the method may be an alternative tool for classification using the expression data. |
|
تصویری از مقاله ترجمه و تایپ شده در نرم افزار ورد |
|
|
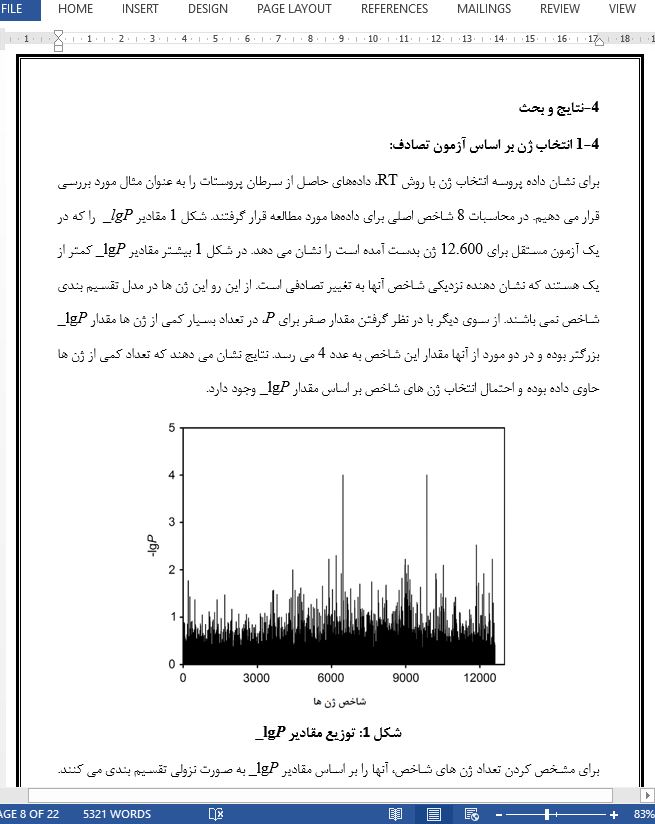
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی | |
| عنوان فارسی مقاله: |
انتخاب ژن های مهم با استفاده از تست تصادفی برای رده بندی سرطان با داده های بیان ژن |
| عنوان انگلیسی مقاله: |
Selecting significant genes by randomization test for cancer classification using gene expression data |
|
|
|