این مقاله انگلیسی ISI در نشریه اسپرینگر در 9 صفحه در سال 2018 منتشر شده و ترجمه آن 20 صفحه میباشد. کیفیت ترجمه این مقاله ویژه – طلایی ⭐️⭐️⭐️ بوده و به صورت کامل ترجمه شده است.
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی | |
| عنوان فارسی مقاله: |
شناسایی گوینده در گفتار نجوایی: تحقیق در مورد ویژگی های تيمبرل و اندازه فاصله KNN |
| عنوان انگلیسی مقاله: |
Speaker identification of whispering speech: an investigation on selected timbrel features and KNN distance measures |
|
|
|
| مشخصات مقاله انگلیسی (PDF) | |
| سال انتشار مقاله | 2018 |
| تعداد صفحات مقاله انگلیسی | 9 صفحه با فرمت pdf |
| نوع مقاله | ISI |
| نوع ارائه مقاله | ژورنال |
| رشته های مرتبط با این مقاله | مهندسی کامپیوتر |
| گرایش های مرتبط با این مقاله | مهندسی الگوریتم ها و محاسبات، هوش مصنوعی |
| چاپ شده در مجله (ژورنال) | مجله بین المللی تکنولوژی گفتار – International Journal of Speech Technology |
| کلمات کلیدی | شناسایی گویشور، توصیف گر طنین صوتی، گفتار نجوایی، تابع فاصله، نزدیک ترین همسایه K، ماتریس آمیختگی |
| کلمات کلیدی انگلیسی | Speaker identification, Timbrel audio descriptors, Whispering speech, Distance function, K-Nearest neighbor, Confusion matrix |
| ارائه شده از دانشگاه | گروه E & TC، مرکز تحقیقات RSCoE، دانشگاه S.P. Pune، هند |
| نویسندگان | V. M. Sardar, S. D. Shirbahadurkar |
| نمایه (index) | Scopus – Master journal List |
| شناسه شاپا یا ISSN | ISSN 1572-8110 |
| شناسه دیجیتال – doi | https://doi.org/10.1007/s10772-018-9527-4 |
| ایمپکت فاکتور(IF) مجله | 1.218 در سال 2018 |
| شاخص H_index مجله | 24 در سال 2019 |
| شاخص SJR مجله | 0.222 در سال 2018 |
| شاخص Q یا Quartile (چارک) | Q3 در سال 2018 |
| بیس | نیست ☓ |
| مدل مفهومی | ندارد ☓ |
| پرسشنامه | ندارد ☓ |
| متغیر | دارد ✓ |
| رفرنس | دارد ✓ |
| کد محصول | 9575 |
| لینک مقاله در سایت مرجع | لینک این مقاله در سایت Springer |
| نشریه اسپرینگر |  |
| مشخصات و وضعیت ترجمه فارسی این مقاله (Word) | |
| وضعیت ترجمه | انجام شده و آماده دانلود در فایل ورد و PDF |
| کیفیت ترجمه | ویژه – طلایی ⭐️⭐️⭐️ |
| تعداد صفحات ترجمه تایپ شده با فرمت ورد با قابلیت ویرایش | 20 صفحه با فونت 14 B Nazanin |
| ترجمه عناوین تصاویر و جداول | ترجمه شده است ✓ |
| ترجمه متون داخل تصاویر | ترجمه نشده است ☓ |
| ترجمه متون داخل جداول | ترجمه نشده است ☓ |
| درج تصاویر در فایل ترجمه | درج شده است ✓ |
| درج جداول در فایل ترجمه | درج شده است ✓ |
| درج فرمولها و محاسبات در فایل ترجمه | به صورت عکس درج شده است ✓ |
| منابع داخل متن | درج نشده است ☓ |
| فهرست مطالب |
|
چکیده 1- مقدمه 2- توصیف سیستم 2-1 دیتابیس گویشور 2-2 الگوریتم ترکیبی انتخاب ویژگی ها 2-3 توصیف کننده های صوتی انتخاب شده 2-4 طبقه بندی کننده نزدیک ترین همسایه K (KNN) 3- نتایج 3-1 صحت شناسایی برای حالت های مختلف کلام همراه با ویژگی های مختلف و توابع فاصله و برای افزایش تعداد ویژگی ها 3-2 ماتریس در هم ریختگی 4- جمع بندی |
| بخشی از ترجمه |
|
چکیده شناسایی گویشور از گفتار نجوایی، در زمینه ی علوم قانونی و بسیاری دیگر از کاربرد ها، دارای اهمیت بسیار زیادی می باشد. گفتار نجوایی از نظر مشخصات، نسبت به گفتار عادی تغییرات زیاد و مهمی را دارد. ازین رو وظیفه ی شناسایی با استفاده از این گفتار دشوار می شود. این مقاله، روش استفاده از ویژگی های طنین با عملکرد خوب از طریق روش انتخاب هیبریدی ( ترکیبی) و تاثیر معیار های فاصله ای مورد استفاده در کلاسیفایر KNN بر روی صحت شناسایی را ارائه می کند. نتایج استفاده از ویژگی های طنین با ویژگی های MFCC مقایسه شده است ؛ صحت مورد اول از روش دوم بیشتر می باشد. کلاسیفایر KNN با محتمل ترین تابع فاصله برای دیتابیس گفتار نجوایی مانند Euclidean و City-block با یکدیگر مقایسه شده اند. ترکیب ویژگی های طنین و کلاسیفایر KNN با تابع فاصله ی City Block ، بیشترین صحت شناسایی را برای ما ایجاد کرد.
4- جمع بندی |
| بخشی از مقاله انگلیسی |
|
Abstract Speaker identification from the whispered speech is of great importance in the field of forensic science as well as in many other applications. Whispered speech shows many changes in the characteristics to its neutral counterpart. Hence the task of identification becomes difficult. This paper presents the use of only well-performing timbrel features selected by Hybrid selection method and effect of distance measures used in KNN classifier on the identification accuracy. The results using timbrel features are compared with MFCC features; the accuracy with the former is observed higher. KNN classifier with most probable distance function suitable for a whispered database like Euclidean and City-block are also compared. The combination of timbrel features and KNN classifiers with city block distance function have reported the highest identification accuracy.
4 Conclusion We have selected well-performing audio descriptors only by using Hybrid selection algorithm for speaker identification with neutral and whispered speech. The selected features are found good in terms of the discrimination ability from their inter-correlation. The correlation analysis also confirmed the intra-speaker similarity and interspeaker dissimilarity with respect to their feature vector values. The results with a combination of timbrel features namely zero-crossing rate, roll-off, irregularity, brightness, roughness, and Mel-frequency cepstral coefficient (MFCC) are compared in three training and testing modes of speech i.e. neutral–neutral, whisper–whisper, and, neutral whisper. However, neutral training and whispered testing for speaker identification is targeted. Timbrel features reported 6% increase in identification accuracy compared to MFCC features for 35 speakers with neutral-whisper condition. The second set of experiments aimed to find better distance function among Euclidean and City-block. Accuracy by using City-block is found 6% more compared to Euclidean distance at similar conditions. Accuracy using k=3, City-block distance and, timbrel features is observed with increasing number of speakers. Accuracy decreases with increasing database. However, decrease in accuracy is relatively lower which proves that timbrel features are robust enough (Table 8).
|
|
تصویری از مقاله ترجمه و تایپ شده در نرم افزار ورد |
|
|
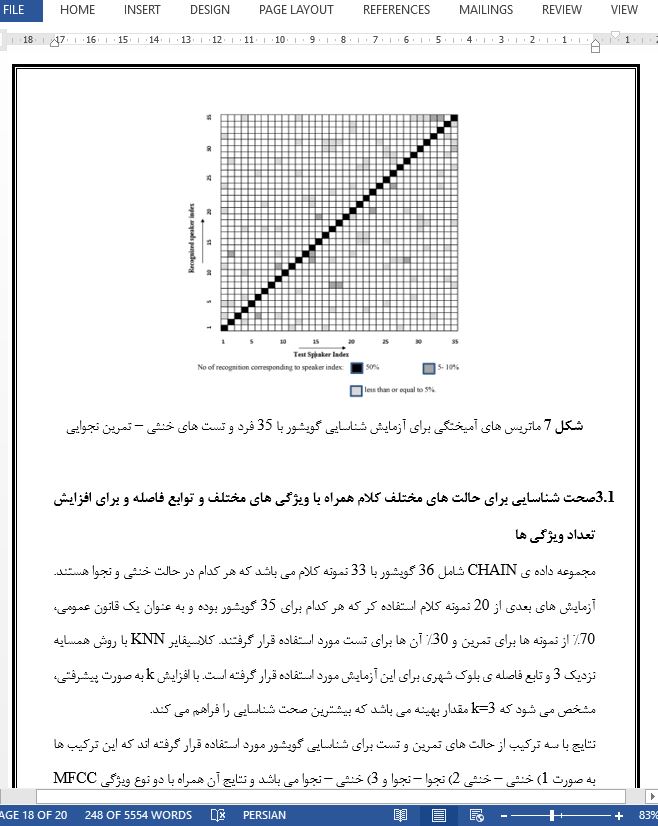
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی | |
| عنوان فارسی مقاله: |
شناسایی گوینده در گفتار نجوایی: تحقیق در مورد ویژگی های تيمبرل و اندازه فاصله KNN |
| عنوان انگلیسی مقاله: |
Speaker identification of whispering speech: an investigation on selected timbrel features and KNN distance measures |
|
|
|