این مقاله انگلیسی ISI در نشریه IEEE در 5 صفحه در سال 2016 منتشر شده و ترجمه آن 11 صفحه میباشد. کیفیت ترجمه این مقاله ویژه – طلایی ⭐️⭐️⭐️ بوده و به صورت کامل ترجمه شده است.
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی | |
| عنوان فارسی مقاله: |
ساختارکاوی وب با الگوریتم پیش پردازش داده ها |
| عنوان انگلیسی مقاله: |
Data Preprocessing Algorithm for Web Structure Mining |
|
|
|
| مشخصات مقاله انگلیسی (PDF) | |
| سال انتشار | 2016 |
| تعداد صفحات مقاله انگلیسی | 5 صفحه با فرمت pdf |
| رشته های مرتبط با این مقاله | مهندسی کامپیوتر، مهندسی فناوری اطلاعات |
| گرایش های مرتبط با این مقاله | شبکه های کامپیوتری، اینترنت و شبکه های گسترده و رایانش ابری |
| چاپ شده در کنفرانس | پنجمین کنفرانس بین المللی محاسبات و سیستم های ارتباطی سازگار با محیط زیست |
| کلمات کلیدی | داده کاوی، وب کاوی، ساختارکاوی وب، پیش پردازش داده ها |
| ارائه شده از دانشگاه | گروه ریاضی و کاربردهای کامپیوتری، موسسه ملی فناوری مولانا آزاد، بپال، هند |
| نویسندگان | Suvarn Sharma, Amit Bhagat |
| شناسه شاپا یا ISSN | ISBN 978-1-5090-4359-0 |
| شناسه دیجیتال – doi | http://doi.org/10.1109/Eco-friendly.2016.7893249 |
| رفرنس | دارد ✓ |
| کد محصول | 9353 |
| لینک مقاله در سایت مرجع | لینک این مقاله در سایت IEEE |
| نشریه آی تریپل ای | |
| مشخصات و وضعیت ترجمه فارسی این مقاله (Word) | |
| وضعیت ترجمه | انجام شده و آماده دانلود |
| کیفیت ترجمه | ویژه – طلایی ⭐️⭐️⭐️ |
| تعداد صفحات ترجمه تایپ شده با فرمت ورد با قابلیت ویرایش | 11 صفحه با فونت 14 B Nazanin |
| ترجمه عناوین تصاویر و جداول | ترجمه شده است ✓ |
| ترجمه متون داخل تصاویر | ترجمه نشده است ☓ |
| ترجمه متون داخل جداول | ترجمه نشده است ☓ |
| درج تصاویر در فایل ترجمه | درج شده است ✓ |
| درج جداول در فایل ترجمه | درج شده است ✓ |
| درج فرمولها و محاسبات در فایل ترجمه | به صورت عکس درج شده است ✓ |
| منابع داخل متن | درج نشده است ☓ |
| فهرست مطالب |
|
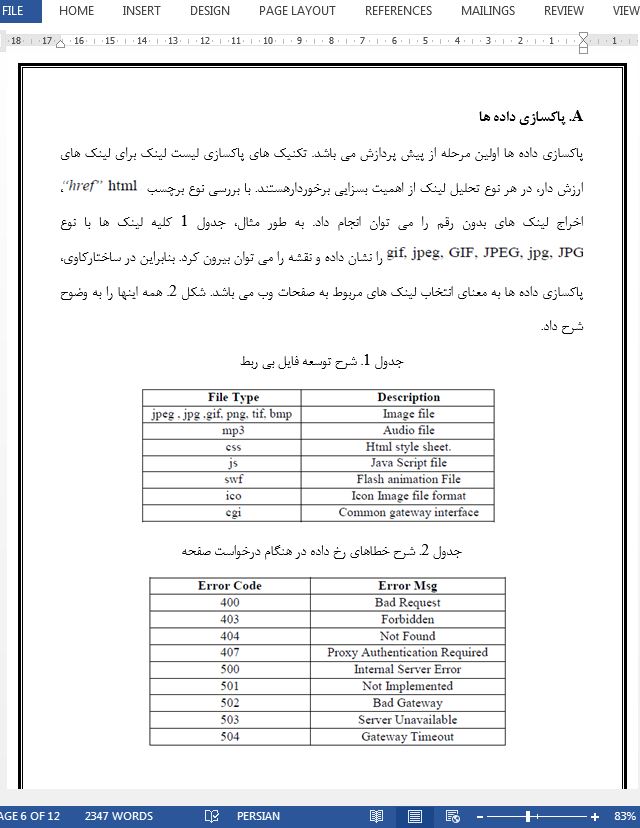
چکیده 1- مقدمه A- ساختارکاوی وب B- داده های وب 2- جمع آوری داده ها 3- پیش پردازش داده ها 4- پیش پردازش ساختار A- پاکسازی داده ها B- یکپارچه سازی داده ها C- تبدیل داده ها D- کاهش داده ها 5- کلیات و تعریف مسئله 6- الگوریتم 7- نتایج 8- کاربردهای ساختارکاوی وب 9- نتیجه گیری |
| بخشی از ترجمه |
|
چکیده شبکه جهانی وب یک مجموعه بی نهایت بزرگ از اطلاعات می باشد، به عبارتی فراتر از حد تصور ما می باشد. آن اطلاعات کافی طبق نیاز کاربر ارائه می دهد. وب به سرعت رو به افزایش می باشد به گونه ای که روزانه تقریباً 70 میلیون صفحه اضافه می گردد. کشف دانش روی داده های وب، وب کاوی نامیده می شود. ساختارکاوی وب مبتنی بر تحلیل الگوها از ساختار هایپرلینک در وب می باشد. درست مثل داده کاوی، وب کاوی نیز دارای چهار مرحله می باشد، به عبارتی جمع آوری داده ها، پیش پردازش، کشف دانش و تحلیل دانش. این مقاله مبتنی بر دو مرحله جمع آوری و پیش پردازش داده ها می باشد. جمع آوری داده ها به جمع آوری داده های مورد نیاز برای تحلیل اشاره می کند. پیش پردازش به عنوان یک مرحله مهم از ساختارکاوی وب در نظر گرفته است ، زیرا داده های موجود روی وب غیر ساختاریافته، ناهمگن و نویزی هستند.
1- مقدمه داده کاوی به فرایند تحلیل داده ها از رویکردهای مختلف و جمع بندی آنها در اطلاعات مفید گفته می شود. با رشد وب، حال مقدار بزرگی از داده ها برای کاربران روی وب موجود می باشد. داده های پیش پردازش شده کارایی و مقیاس پذیری مراحل بعدی ساختارکاوی وب را بهبود می بخشند. این کار را می توان در فازهای مختلفی انجام داد: ترکیب داده ها، استخراج داده ها، تمیز کردن یا پاکسازی داده ها، استخراج لینک ها و فراداده ها (متادیتا)، تکمیل مسیر و غیره انجام داد. ترکیب داده ها شامل جمع آوری صفحات جمع آوری شده از وب سرورهای مختلف می شود. از استخراج داده ها برای استخراج لوگ داده ها طبق مدت زمان تحلیل استفاده می شود. پاکسازی داده ها به پاکسازی لینک های بی ربط اشاره می کند که برای تحلیل ساختار مفید نیستند، به عبارتی فایلهای چند رسانه ای، ورقه سبک html و غیره. |
| بخشی از مقاله انگلیسی |
|
Abstract World Wide Web is an extremely large collection of information, i.e. beyond our imagination. It provides enough information according to user’s need. Web is rising dreadfully as approximately 70 million pages are added daily. Knowledge Discovery on web data is referred as Web Mining. Web Structure Mining based on the analysis of patterns from hyperlink structure in the web. Like as Data Mining, Web Mining has four stages i.e. Data Collection, Preprocessing, Knowledge Discovery and Knowledge Analysis. This paper based on the first two stages Data collection and Preprocessing. Data collection is to collect the data required for analysis. Data preprocessing is considered as an important stage of Web Structure mining because of data available on web is unstructured, heterogeneous and noisy.
I- INTRODUCTION Data mining is the process of analyzing data from different perspectives and summarizing it into useful information. With the growth of Web, a large amount of data is now available for users on web. Web .Preprocessed data improves efficiency and scalability of later stages of Web structure mining. This can be done in several phases: Data fusion, Data Extraction, Data cleaning, links and metadata extraction, Path completion etc. Data fusion includes collecting of pages collected from various Web servers. Data extraction is used to extract log data according to time duration of analysis. Data cleaning refers to the cleaning of irrelevant links which is not useful for the purpose of structure analysis i.e. multimedia files html style sheet etc.
|
|
تصویری از مقاله ترجمه و تایپ شده در نرم افزار ورد |
|
|
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی | |
| عنوان فارسی مقاله: |
ساختارکاوی وب با الگوریتم پیش پردازش داده ها |
| عنوان انگلیسی مقاله: |
Data Preprocessing Algorithm for Web Structure Mining |
|
|
|