| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی | |
| عنوان فارسی مقاله: |
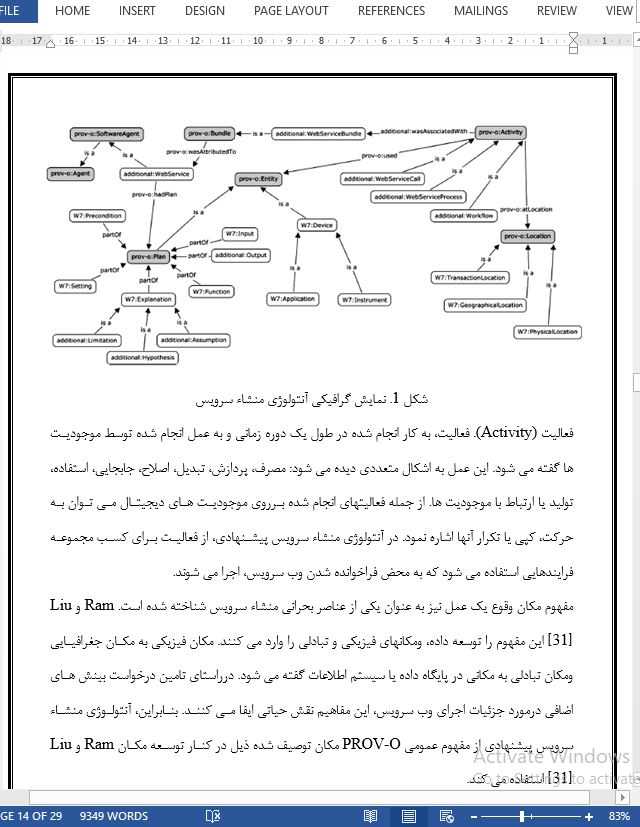
استفاده رویکرد منشا محور برای توصیف و کشف وب سرویس معنایی |
| عنوان انگلیسی مقاله: |
A provenance-based approach to semantic web service description and discovery |
|
|
|
| مشخصات مقاله انگلیسی (PDF) | |
| سال انتشار | 2014 |
| تعداد صفحات مقاله انگلیسی | 10 صفحه با فرمت pdf |
| نوع مقاله | ISI |
| نوع نگارش | مقاله پژوهشی (Research article) |
| نوع ارائه مقاله | ژورنال |
| رشته های مرتبط با این مقاله | مهندسی کامپیوتر، مهندسی فناوری اطلاعات |
| گرایش های مرتبط با این مقاله | مهندسی نرم افزار، اینترنت و شبکه های گسترده، رایانش ابری |
| چاپ شده در مجله (ژورنال) | سیستم های پشتیبانی تصمیم – Decision Support Systems |
| کلمات کلیدی | کشف وب سرویس، وب سرویس معنایی، آنتولوژی، منشاء (منبع) |
| کلمات کلیدی انگلیسی | Web service discovery – Semantic web service – Ontology – Provenance |
| ارائه شده از دانشگاه | گروه فناوری اطلاعات و علوم مدیریت، دانشگاه Marymount، ایالات متحده آمریکا |
| نمایه (index) | Scopus – Master journals – JCR |
| نویسندگان | Tom Narock، Victoria Yoon، Sal March |
| شناسه شاپا یا ISSN | ISSN 0167-9236 |
| شناسه دیجیتال – doi | https://doi.org/10.1016/j.dss.2014.04.007 |
| ایمپکت فاکتور(IF) مجله | 5.421 در سال 2018 |
| شاخص H_index مجله | 127 در سال 2019 |
| شاخص SJR مجله | 1.536 در سال 2018 |
| شاخص Q یا Quartile (چارک) | Q1 در سال 2018 |
| بیس | است ✓ |
| مدل مفهومی | ندارد ☓ |
| پرسشنامه | ندارد ☓ |
| متغیر | دارد ✓ |
| رفرنس | دارای رفرنس در داخل متن و انتهای مقاله ✓ |
| کد محصول | 9753 |
| لینک مقاله در سایت مرجع | لینک این مقاله در نشریه Elsevier |
| نشریه الزویر |  |
| مشخصات و وضعیت ترجمه فارسی این مقاله (Word) | |
| وضعیت ترجمه | انجام شده و آماده دانلود در فایل ورد و PDF |
| کیفیت ترجمه | طلایی⭐️ |
| تعداد صفحات ترجمه تایپ شده با فرمت ورد با قابلیت ویرایش | 29 صفحه (شامل 1 صفحه رفرنس انگلیسی) با فونت 14 B Nazanin |
| ترجمه عناوین تصاویر و جداول | ترجمه شده است ✓ |
| ترجمه متون داخل تصاویر | ترجمه نشده است ☓ |
| ترجمه متون داخل جداول | ترجمه نشده است ☓ |
| درج تصاویر در فایل ترجمه | درج شده است ✓ |
| درج جداول در فایل ترجمه | درج شده است ✓ |
| منابع داخل متن | درج نشده است ☓ |
| منابع انتهای متن | به صورت انگلیسی درج شده است ✓ |
| فهرست مطالب |
|
چکیده 1- مقدمه 2- مثال انگیزه بخش از علم الکترونیکی 3- کارهای مرتبط 4- آنتولوژی منشاء سرویس 1- 4- پایه و اساس نظری 2- 4- بنیان آنتولوژی منشاء سرویس 3- 4- خلق آنتولوژی منشاء سرویس 4- 4- اجزای آنتولوژی 5- اتصال به استانداردهای موجود 6- ارزیابی 1- 6- کیفیت آنتولوژی منشاء سرویس 2- 6- مطلوبیت کشف مبتنی بر منشاء 7- بحث 8- خلاصه و نتایج |
| بخشی از ترجمه |
|
چکیده در حوزه های ادغام کسب و کار با کسب و کار، محاسبات توزیع شده و ادغام اپلیکیشن سازمانی، وب سرویس ها به عناصری مشترک (به فرض غیر ضروری)، تبدیل شده اند. با این وجود، استانداردهای مبتنی بر XML برای توصیف وب سرویس، فقط نمایش نحوی ورودی و خروجی سرویس را رمزگذاری می کنند. معنای حقیقی این اصطلاحات، تعاریف رسمی آنها، و ارتباط آنها با مفاهیم دیگر مطرح نشده است. این مسئله موجب بروز چالش هایی برای اهرم بندی وب سرویس ها در توسعه قابلیت های نرم افزار می شود. با رشد تعداد سرویس ها و افزایش اختصاصی بودن نیازهای کاربران، توانایی یافتن یک سرویس مناسب برای یک اپلیکیشن خاص، سخت می شود. برای غلبه بر این چالش، وب سرویس های معنایی پیشنهاد شدند. برای کشف وب سرویس ها، وب سرویس های معنایی از آنتولوژیهایی جهت یافتن تطابق ها بین نیازمندیهای کاربر و قابلیت های سرویس استفاده می کنند. استدلال محاسباتی عرضه شده توسط آنتولوژیها، به کاربران امکان یافتن طبقه بندیهایی را می دهد که صریحاً تعریف نشدند. با این حال، روشهایی برای کشف وب سرویس معنایی وجود دارد. براساس علم الکترونیکی، که آنالوگ کسب و کار الکترونیکی است، یکی از روشهای بکاررفته، از توصیف معنایی تفصیلی و عمیق ورودیها و خروجیهای وب سرویس حمایت می کند. با این وجود، این روش قبل از پیشرفتهای اخیر در تحقیق منشاء (منبع) و وب معنایی واقع شده و وسعت کاربرد آن در خارج از حوزه علم الکترونیکی، روشن نیست. در اینجا از طریق آزمایش درون فردی به کشف این سئوال پرداخته، این روش را با تحقیق فعلی در زمینه منشا، وب معنایی، و استانداردهای وب سرویس توسعه داده، و شیوه ای یکپارچه برای توصیف و کشف وب سرویس، توسعه و به روش تجربی مورد ارزیابی قرار می دهیم. مفاهیم لازم برای الگوریتم های پیشرفته تر کشف وب سرویس و واسط های کاربر نیز مطرح شده است.
8- خلاصه و نتایج استفاده از اطلاعات منشاء وب سرویس، عنصری حیاتی برای کشف کارآمد وب سرویس در علم الکترونیکی به حساب می آید. با این وجود، در مورد کلیات این روش، اطلاعات کمی موجود بود. در مرجع[66] پیشنهاد شده است که منشاء، نقش مهم و اساسی در زیرساخت های دیجیتال در حال ظهور ایفا می کند و برای تحقیق جنبه های نظری و مفهومی اش، باید گام های مهمی برداشته شود. اما، منشاء همچنان به صورت ناقص، نامطمئن و درست تعریف نشده باقی می ماند. براساس نظریه آنتولوژیکی Bung، با ادغام PROV-O و W7 با مفاهیم پیشنهادی که امکان کپسول بندی منحصر به فرد مولفه های سرویس و توجیه های مربوطه را فراهم می آورد، آنتولوژی منشاء سرویس جامعی توسعه داده ایم. چنین آنتولوژی، به خالقین سرویس امکان تامین کلیه اطلاعات منشاء ضروری وب سرویس ها را داده و بدین طریق کشف وب سرویس را بهبود می بخشد. |
| بخشی از مقاله انگلیسی |
|
Abstract Web services have become common, if not essential, in the areas of business-to-business integration, distributed computing, and enterprise application integration. Yet the XML-based standards for web service descriptions encode only a syntactic representation of the service input and output. The actual meaning of these terms, their formal definitions, and their relationships to other concepts are not represented. This poses challenges for leveraging web services in the development of software capabilities. As the number of services grows and the specificity of users’ needs increases, the ability to find an appropriate service for a specific application is strained. In order to overcome this challenge, semantic web services were proposed. For the discovery of web services, semantic web services use ontologies to find matches between user requirements and service capabilities. The computational reasoning afforded by ontologies enables users to find categorizations that weren’t explicitly defined. However, there are a number of methodological variants on semantic web service discovery. Based on e-Science, an analog to e-Business, one methodology advocates deep and detailed semantic description of a web service’s inputs and outputs. Yet, this methodology predates recent advances in semantic web and provenance research, and it is unclear the extent to which it applies outside of e-Science. We explore this question through a within-subjects experiment and we extend this methodology with current research in provenance, semantic web, and web service standards, developing and empirically evaluating an integrated approach to web service description and discovery. Implications for more advanced web service discovery algorithms and user interfaces are also presented.
8- Summary and conclusions Utilizing a web service’s provenance information has proven vital to efficient web service discovery in e-Science [11]. Yet, little was known about the generality of this methodology. It has been suggested [66] that provenance will play a central role in emerging digital infrastructures and important steps have been taken to research its theoretical and conceptual aspects. However, provenance remains incomplete, unreliable, and ill-defined [66]. Drawing upon Bunge’s ontological theory [27,28], we have developed a comprehensive service provenance ontology by integrating PROV-O [33] and W7 [31] with our own concepts allowing for a unique encapsulation of a service’s components and their associated justifications. Such an ontology enables service creators to supply all necessary provenance information of web services, thereby improving web service discovery. |
|
تصویری از مقاله ترجمه و تایپ شده در نرم افزار ورد |
|
|
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی | |
| عنوان فارسی مقاله: |
استفاده رویکرد منشا محور برای توصیف و کشف وب سرویس معنایی |
| عنوان انگلیسی مقاله: |
A provenance-based approach to semantic web service description and discovery |
|
|
|