این مقاله انگلیسی ISI در نشریه Ijimt در 7 صفحه در سال 2014 منتشر شده و ترجمه آن 17 صفحه میباشد. کیفیت ترجمه این مقاله ویژه – طلایی ⭐️⭐️⭐️ بوده و به صورت کامل ترجمه شده است.
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی | |
| عنوان فارسی مقاله: |
بررسی الگوریتم های خوشه بندی K-Means وC-Means برای توسعه محصول تشخیص نفوذ |
| عنوان انگلیسی مقاله: |
A Study of K-Means and C-Means Clustering Algorithms for Intrusion Detection Product Development |
|
|
|
| مشخصات مقاله انگلیسی | |
| فرمت مقاله انگلیسی | pdf و ورد تایپ شده با قابلیت ویرایش |
| سال انتشار | 2014 |
| تعداد صفحات مقاله انگلیسی | 7 صفحه با فرمت pdf |
| نوع مقاله | ISI |
| نوع ارائه مقاله | ژورنال |
| رشته های مرتبط با این مقاله | مهندسی کامپیوتر |
| گرایش های مرتبط با این مقاله | مهندسی الگوریتم ها و محاسبات، مهندسی نرم افزار |
| چاپ شده در مجله (ژورنال) | مجله بین المللی نوآوری، مدیریت و فناوری – International Journal of Innovation, Management and Technology |
| کلمات کلیدی انگلیسی | K-Means, C-Means, KDDCup99, GureKDD, NSLKDD |
| ارائه شده از دانشگاه | انستیتوی ملی فناوری، روركلا، هند |
| نویسندگان | Santosh Kumar Sahu – Sanjay Kumar Jena |
| شناسه دیجیتال – doi | https://doi.org/10.7763/IJIMT.2014.V5.515 |
| بیس | نیست ☓ |
| مدل مفهومی | ندارد ☓ |
| پرسشنامه | ندارد ☓ |
| متغیر | ندارد ☓ |
| رفرنس | دارای رفرنس در داخل متن و انتهای مقاله ✓ |
| کد محصول | 10985 |
| نشریه | Ijimt |
| مشخصات و وضعیت ترجمه فارسی این مقاله | |
| فرمت ترجمه مقاله | pdf و ورد تایپ شده با قابلیت ویرایش |
| وضعیت ترجمه | انجام شده و آماده دانلود |
| کیفیت ترجمه | ویژه – طلایی ⭐️⭐️⭐️ |
| تعداد صفحات ترجمه تایپ شده با فرمت ورد با قابلیت ویرایش | 17 (1 صفحه رفرنس انگلیسی) صفحه با فونت 14 B Nazanin |
| ترجمه عناوین تصاویر و جداول | ترجمه شده است ✓ |
| ترجمه متون داخل تصاویر | ترجمه شده است ✓ |
| ترجمه متون داخل جداول | ترجمه شده است ✓ |
| ترجمه ضمیمه | ندارد ☓ |
| ترجمه پاورقی | ندارد ☓ |
| درج تصاویر در فایل ترجمه | درج شده است ✓ |
| درج جداول در فایل ترجمه | درج شده است ✓ |
| درج فرمولها و محاسبات در فایل ترجمه | به صورت عکس درج شده است ✓ |
| منابع داخل متن | به صورت عدد درج شده است ✓ |
| منابع انتهای متن | به صورت انگلیسی درج شده است ✓ |
| فهرست مطالب |
|
چکیده I مقدمه II روش های خوشه بندی III پیاده سازی IV بررسی و نتیجه گیری V نتیجه گیری |
| بخشی از ترجمه |
|
چکیده با توسعه اینترنت و نرم افزارهای مبتنی بر اینترنت، محل کسب و کار در سرتاسر دنیا گسترده شده است. به دلیل رقابتهای بی حد و حصر در تجارت، رقبا در تلاش برای نابودی یکدیگر میباشند. از این رو بایستی برای طراحی محصول شیوههای امنی بکار گرفته شوند. در هر سازمانی برای حفاظت از نرم افزارها در مقابل نفوذگر، سیستم تشخیص نفوذ از مهمترین ضروریات میباشد. در مدلهای تشخیص نفوذ به مجموعه بزرگی از دادههای آموزشی نیازمندیم. در نتیجه الگوریتمهای پیچیده و منابع محاسباتی بسیاری لازم میباشد. در سیستم تشخیص نفوذ، الگوریتمهای خوشهبندی به منظور تفکیک فعالیتهای عادی از فعالیتهای غیرعادی بکار گرفته میشوند. انتخاب الگوریتم خوشهبندی مناسب کاری چالشبرانگیز است. در این مقاله، مقایسهای میان روشهای خوشهبندی K-Means و C-Means بر روی مجموعه دادههای نفوذ انجام شده است. این شبیهسازی شامل تمامی معیارهای نزدیکی روشهای خوشهبندی K-Means و C-Means است. دقت این دو الگوریتم خوشهبندی با استفاده از ماتریس درهمریختگی مورد قیاس قرار میگیرد. نتیجه نشان میدهد که روش K-Means خوشهبندی دقیقتری نسبت به روش C-Means ارائه میدهد. بنابراین برای طراحی محصول تشخیص نفوذ هوشمند، روش K-Means انتخاب بهتری است.
I. مقدمه در حال حاضر طراحی محصولات نرم افزاری هوشمند که در برابر حملات روزانه دوام آورند، بسیار ضروری است. برای هر شرکت نرم افزاری، توسعه آینده نگرانه محصول ضروری ترین مساله است. شرکت ها بایستی به این مساله توجه کنند که محصولشان چگونه در محیط واسطه ی ناامنی مانند اینترنت دوام خواهد آورد. برای تاب آوردن این محصولات در برابر فعالیت های نامعمول، نیازمند مفاهیم علمی مختلفی هستیم. اصطلاح نفوذ مجموعه ی اقداماتی را شامل می شود که محرمانگی، صحت و دسترسی به منابع اطلاعاتی را به خطر می اندازد. تشخیص نفوذ فرآیند نظارت بر فعالیت های در حال انجام در شبکه و بررسی بسته های (پکت ) ورودی یا خروجی شبکه می باشد. سیستم تشخیص نفوذ این فرآیند را به طور خودکار انجام داده و از اقدامات نفوذی مقابله می کند. این اقدامات ممکن است از درون سیستم یا خارج از آن صورت گرفته باشند. نفوذگرها را می توان به انواع clandestine، misfeasor و masquerader [1] تقسیم بندی کرد.
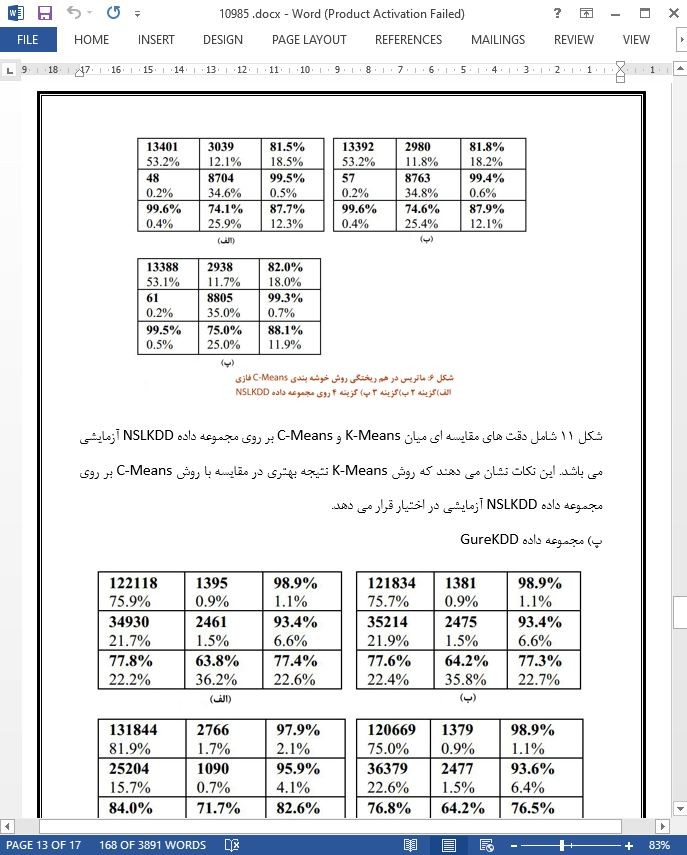
V نتیجه گیری در این مقاله دو روش خوشه بندی بر اساس مجموعه داده های نفوذ بررسی شده اند. این روش های خوشه بندی توسط مجموعه داده های نفوذ با معیارهای فاصله متفاوت پیاده سازی، محاسبه و مقایسه شده اند. مقایسه انجام شده در این مقاله حول دقت خوشه بندی دو روش مذکور تمرکز کرده و با ملاحظه دقیق در محاسبات مربوط به دقت و سایر معیارهای کارایی انجام شده است. به این نتیجه رسیدیم که الگوریتم خوشه بندی K-Means بر روی این مجموعه داده ها، دقت بیشتر و با صرف مدت زمان کوتاهتری نسبت به الگوریتم خوشه بندی C-Means ارائه می دهد. نیازی نیست که روش های خوشه بندی مورد مطالعه در این مقاله، به تنهایی برای پیش بینی حملات مورد استفاده قرار بگیرند. نظر به اینکه مراکز ثقل به طور تصادفی انتخاب می شوند، کلاس افرازبندی هم ممکن است تغییر کرده یا در هر اجرا تکامل یابد. بنابراین برای دستیابی به دقت بالاتر بهتر است با سایر الگوریتم های داده کاوی بصورت تلفیقی استفاده شود. |
| بخشی از مقاله انگلیسی |
|
Abstract The increase in Internet and Internet based application, the business premises have now spread throughout the world. Due to the extreme competitions among the business, one tries to demolish other. Hence, secure product design techniques should be adopted. To protect the applications from intruder, intrusion detection system becomes utmost requirement for every organization. In intrusion detection models enormous quantity of training data is required. As a result, sophisticated algorithms and high computational resources are required. In Intrusion Detection System, to separate normal activities from abnormal activities clustering algorithms are used. To select an efficient clustering algorithm is a challenging task. In this paper, a comparison has been made between K-Means and C-Means clustering on intrusion datasets. The simulation contains all proximity measures of K-Means and C-Means clustering techniques. The accuracy of these clustering algorithms is compared using the confusion matrix. The result shows that K-Means provides better clustering accuracy in comparison with C-Means. Therefore, to design intelligent intrusion detection product K-Means is a better option.
I. INTRODUCTION In the present day it is highly essential to design intelligence software products which can withstand zero day attacks. The innovative product development is utmost essential to every software firm. They should focus on how the product is survive in an insecure medium like the internet. Interdisciplinary concepts are required to tolerate the unusual activities. The term intrusion comprises a set of attempts to compromise the confidentiality, integrity and availability of information resources. Intrusion detection is the process of monitoring the events in the system and analyzing the network packets to or from the network. Intrusion detection system automates the process and counteract the intrusive efforts. The intrusive efforts can be caused by insiders or outsiders in the system. The intruder can be classified as clandestine, misfeasor and masquerader [1].
V. CONCLUSION Two clustering techniques based on intrusion datasets have been reviewed in this paper. These clustering techniques with different similarity measures are implemented, evaluated and compared using intrusion datasets. The comparative study discussed here is concerned with the accuracy of each algorithm, with care being taken towards the accuracy in calculation and other performance related measures. It is found that the K-Means clustering algorithm provides better accuracy and consumes less time in comparison to C-Means clustering on these datasets. The clustering techniques discussed here don’t have to be used alone to predict different attacks. As the initial centroids are chosen randomly, the class distribution may change or evolve on each execution. Therefore, it should be used in conjunction with other data mining algorithms for better accuracy. |
|
تصویری از مقاله ترجمه و تایپ شده در نرم افزار ورد |
|
|
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی | |
| عنوان فارسی مقاله: |
بررسی الگوریتم های خوشه بندی K-Means وC-Means برای توسعه محصول تشخیص نفوذ |
| عنوان انگلیسی مقاله: |
A Study of K-Means and C-Means Clustering Algorithms for Intrusion Detection Product Development |
|
|
|