| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی | |
| عنوان فارسی مقاله: |
استفاده از داده کاوی اطلاعات بمنظور پیشرفت خدمات کتابخانه دیجیتالی |
| عنوان انگلیسی مقاله: |
Using data mining to improve digital library services |
|
|
|
| مشخصات مقاله انگلیسی (PDF) | |
| سال انتشار مقاله | 2009 |
| تعداد صفحات مقاله انگلیسی | 16 صفحه با فرمت pdf |
| نوع مقاله | ISI |
| نوع نگارش | مقاله پژوهشی (Research Article) |
| نوع ارائه مقاله | ژورنال |
| رشته های مرتبط با این مقاله | علم اطلاعات و دانش شناسی |
| گرایش های مرتبط با این مقاله | مدیریت کتابخانه های دیجیتال |
| چاپ شده در مجله (ژورنال) | کتابخانه الکترونیکی – The Electronic Library |
| کلمات کلیدی | پایگاه های داده، مدیریت داده ها، کتابخانه های دیجیتال، ارائه خدمت |
| کلمات کلیدی انگلیسی | Digital libraries – Databases – Serbia – Data handling – Service delivery |
| ارائه شده از دانشگاه | دانشکده مطالعات امنیتی، دانشگاه بلگراد، صربستان |
| نمایه (index) | Scopus – Master journals – JCR |
| نویسندگان | Ana Kovacevic، Vladan Devedzic، Viktor Pocajt |
| شناسه شاپا یا ISSN | ISSN 0264-0473 |
| شناسه دیجیتال – doi | https://doi.org/10.1108/02640471011093525 |
| ایمپکت فاکتور(IF) مجله | 1.165 در سال2018 |
| شاخص H_index مجله | 33 در سال 2019 |
| شاخص SJR مجله | 0.537 در سال 2018 |
| شاخص Q یا Quartile (چارک) | Q1 در سال 2018 |
| بیس | نیست ☓ |
| مدل مفهومی | ندارد ☓ |
| پرسشنامه | ندارد ☓ |
| متغیر | ندارد ☓ |
| رفرنس | دارای رفرنس در داخل متن و انتهای مقاله ✓ |
| کد محصول | 10164 |
| لینک مقاله در سایت مرجع | لینک این مقاله در سایت امرالد |
| نشریه امرالد |  |
| مشخصات و وضعیت ترجمه فارسی این مقاله (Word) | |
| وضعیت ترجمه | انجام شده و آماده دانلود در فایل ورد و PDF |
| کیفیت ترجمه | طلایی⭐️ |
| تعداد صفحات ترجمه تایپ شده با فرمت ورد با قابلیت ویرایش | 17 صفحه (1 صفحه رفرنس انگلیسی) با فونت 14 B Nazanin |
| ترجمه عناوین تصاویر و جداول | ترجمه شده است ✓ |
| ترجمه متون داخل تصاویر | ترجمه شده است ✓ |
| ترجمه متون داخل جداول | ترجمه شده است ✓ |
| درج تصاویر در فایل ترجمه | درج شده است ✓ |
| درج جداول در فایل ترجمه | درج شده است ✓ |
| منابع داخل متن | به صورت فارسی درج شده است ✓ |
| منابع انتهای متن | به صورت انگلیسی درج شده است ✓ |
| فهرست مطالب |
|
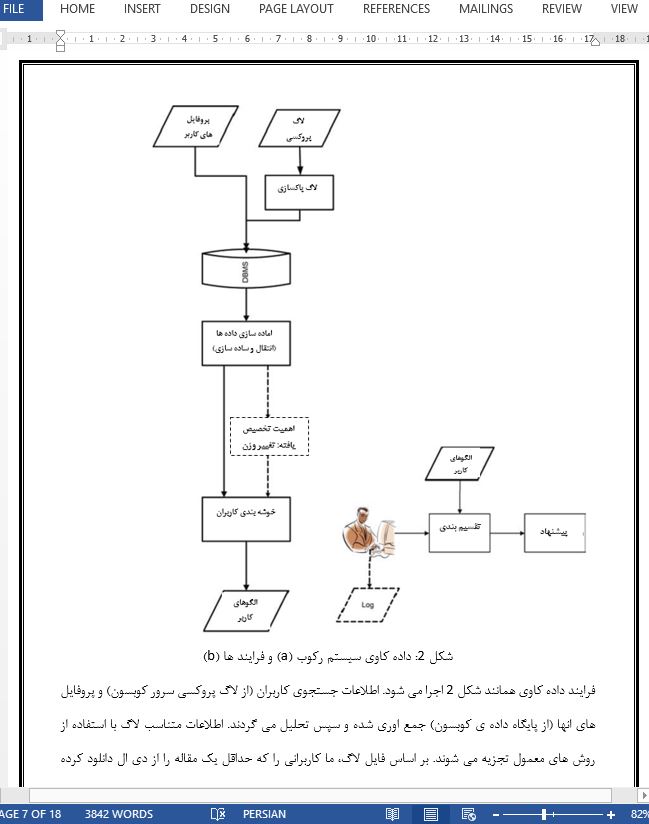
فهرست مطالب 1- مقدمه 2- کارهای مرتبط 3- رکوب 3-1- بررسی کلی فرایند داده کاوی 3-2- پیشنهادات 3-3- اطلاعات 3-4- اماده سازی اطلاعات 3-5- شناسایی الگوهای کاربر 4- ارزیابی 5- نتیجه گیری و کار اینده منابع |
| بخشی از ترجمه |
|
چکیده هدف: این مقاله تلاش می کند تا یک راه حل برای خدمات کتابخانه دیجیتال بر اساس تکنیک های داده کاوی ارائه کند (تقسیم بندی خوشه ای و پیشگویانه)
5- نتیجه گیری و کار اینده: در این مقاله، ما یک راه حل برای ارائه ی خدمات کتابخانه ای به کاربران کتابخانه های دیجیتالی ارائه نمودیم که نه تنها بر اساس اهمیت اماری کاربرد خدمت می باشد بلکه پروفایل های کاربران را نیز بررسی می نماید. پژوهش اصلی ما متمرکز بر کمک به کاربران برای یافتن اسانتر محتوای مرتبط می باشد. ما به این هدف با استفاده از تکنیک های داده کاوی در داده های تاریخی و با ارائه ی خدماتی که کاربران مشابه انتخاب می کنند دست یافتیم. در ابتدا، کاربران را بر اساس پروفایل ها همراه با رفتار پژوهشی شان خوشه بندی نمودیم. نشان داده شده است که کاربران در خوشه ی یکسان اولویت بالایی برای انتخاب خدمات مشابه قائل می شوند. نتایج نشان می دهند که خوشه بندی k میانگین و نایو بیز را می توان با هم برای بهبود ارائه ی خدمات استفاده نمود. نهایتا، مدل خود را در داده های ازمایشی برای ارزیابی درستی ان به کار بردیم. نشان داده شد که درستی کلی رضایت بخش است مخصوصا در خدمات پرکاربرد. در اینده ای نزدیک، قصد داریم تا نمایش تصویری موثری برای ارائه ی خدمات خاص به کاربران و کشف مهم ترین مسائل در نظر بگیریم که کاربران با استفاده از تکنیک های متن کاوی برای تحلیل ایمیل ها یا مصاحبه های ازاد با انها مواجه خواهند شد. |
| بخشی از مقاله انگلیسی |
|
Abstract Purpose This paper aims to propose a solution for recommending digital library services based on data mining techniques (clustering and predictive classification).
5- Conclusion and future work In this paper we have proposed a solution for recommending digital library users a service from the library, based not only on statistical significance of service usage, but also considering the users’ profiles. Our main research was focused on helping users to find relevant material more easily. We achieved it by using data mining techniques on historical data and by recommending the services that similar users would choose. We first clustered the users based on their profiles together with their search behavior. It has been shown that the users in the same cluster have high preference for using similar services. The results show that the k-means clustering and the Naı¨ve Bayes classification can be used together to improve the service recommendation. Finally, we applied our model to test data in order to evaluate its accuracy. It has been shown that the overall accuracy is satisfactory, especially in frequently occurring services. In the near future, we plan to add an effective visual representation for recommending specific services to the users and to discover most significant problems that the users encounter by using text mining techniques to analyze the users’ e-mails or free text interviews. |
|
تصویری از مقاله ترجمه و تایپ شده در نرم افزار ورد |
|
|
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی | |
| عنوان فارسی مقاله: |
استفاده از داده کاوی اطلاعات بمنظور پیشرفت خدمات کتابخانه دیجیتالی |
| عنوان انگلیسی مقاله: |
Using data mining to improve digital library services |
|
|
|