این مقاله انگلیسی ISI در نشریه ساینس دایرکت (الزویر) در 10 صفحه در سال 2017 منتشر شده و ترجمه آن 15 صفحه میباشد. کیفیت ترجمه این مقاله ویژه – طلایی ⭐️⭐️⭐️ بوده و به صورت کامل ترجمه شده است.
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی | |
| عنوان فارسی مقاله: |
بررسی ادبی سیستماتیک روش های تکرار داده ها در محیط های ابری |
| عنوان انگلیسی مقاله: |
A systematic literature review of the data replication techniques in the cloud environments |
|
|
|
| مشخصات مقاله انگلیسی (PDF) | |
| سال انتشار | 2017 |
| تعداد صفحات مقاله انگلیسی | 10 صفحه با فرمت pdf |
| رشته های مرتبط با این مقاله | مهندسی کامپیوتر |
| گرایش های مرتبط با این مقاله | رایانش ابری |
| چاپ شده در مجله (ژورنال) | تحقیقات کلان داده – Big Data Research |
| کلمات کلیدی | رایانش ابری، تکرار داده ها، ایستا، پویا، مروری بر ادبیات سیستماتیک |
| ارائه شده از دانشگاه | گروه مهندسی کامپیوتر، دانشگاه آزاد اسلامی، تبريز، ايران |
| نویسندگان | Bahareh Alami Milani, Nima Jafari Navimipour |
| شناسه شاپا یا ISSN | ISSN 22145796 |
| شناسه دیجیتال – doi | https://doi.org/10.1016/j.bdr.2017.06.003 |
| رفرنس | دارد ✓ |
| کد محصول | 9342 |
| لینک مقاله در سایت مرجع | لینک این مقاله در نشریه Elsevier |
| نشریه الزویر |  |
| مشخصات و وضعیت ترجمه فارسی این مقاله (Word) | |
| وضعیت ترجمه | انجام شده و آماده دانلود |
| کیفیت ترجمه | ویژه – طلایی ⭐️⭐️⭐️ |
| تعداد صفحات ترجمه تایپ شده با فرمت ورد با قابلیت ویرایش | 15 صفحه با فونت 14 B Nazanin |
| ترجمه عناوین تصاویر و جداول | ترجمه شده است ✓ |
| ترجمه متون داخل تصاویر | ترجمه شده است ☓ |
| ترجمه متون داخل جداول | ترجمه شده است ☓ |
| درج تصاویر در فایل ترجمه | درج شده است ✓ |
| درج جداول در فایل ترجمه | درج شده است ✓ |
| منابع داخل متن | به صورت انگلیسی درج شده است ✓ |
| فهرست مطالب |
|
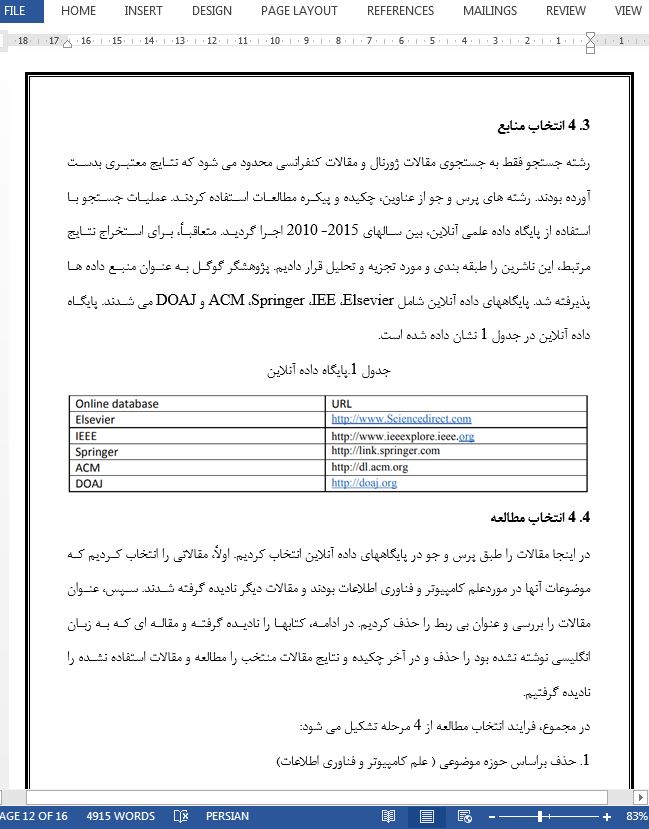
چکیده 1- مقدمه 1- 2 اطلاعات زمینه ای 3- کارهای مرتبط 4. روش تحقیق 1- 4 سئوالات تحقیق 2- 4 پرس و جوی جستجو 3- 4 انتخاب منابع 4- 4 انتخاب مطالعه 5- 4 نتایج 5- استراتژیهای تکرار داده ها 6- نتیجه گیری |
| بخشی از ترجمه |
|
چکیده رایانش ابری چالش های مختلفی مثل استفاده از داده های کپی شده را تجربه می کند. یکی از تکنیک های مهم برای مدیریت داده های انبوه توزیع شده، تکرار داده ها است. هدف ایده عمومی تکرار داده ها، استقرار تکرارها در مکان های مختلف است، حال آنکه تکرارهای مختلفی از یک فایل خاص در نقاط مختلف وجود دارند. یکی ازمطالعه شده ترین پدیده ها در محیط های توزیع شده، تکرار است که کپی های متعددی از داده ها در سایت های متعدد ذخیره می شوند، جایی که سربار ساخت (ایجاد)، حفظ و به روزرسانی کپی ها، موضوعاتی مهم و چالش برانگیز محسوب می شوند. در طول دهه گذشته، اپلیکیشن ها و معماری محاسبات توزیع شده به طور چشمگیری تغییر کرده است و به همین خاطر دارای پروتکل های تکرار هستند. پروتکل های تکرار مختلف، برای اپلیکیشن های گوناگونی مناسب هستند. اما علی رغم اهمیت این موضوع، در محیط ابری به عنوان محیط توزیع شده، این موضوع تا کنون به روش سیستماتیک مورد پژوهش قرار نگرفته است. تکرار داده ها در محیط ابری به دو طبقه تقسیم می شود: روشهای ایستا و پویا . در الگوهای ایستا، تعداد کپی های ساخته شده (ایجاد شده) از شروع ثابت است. تعدادکپی ها، از شروع کار، توسط کاربر یا توسط محیط ابری تعیین می گردد. اما، در الگوریتم پویا و با در نظرگرفتن محیطش، تعدادکپی ها براساس الگوریتم دسترسی کاربر تعیین می شود. هدف این مقاله مرور سیستماتیک تکنیک های تکرار داده ها در این دو گروه اصلی و همچنین بحث راجع به ویژگیهای اصلی هر گروه است.
6- نتیجه گیری |
| بخشی از مقاله انگلیسی |
|
Abstract Cloud computing has various challenges, one of them is using copied data. Data replication is an important technique for distributed mass data management. The aim of the general idea of data replication is placing replications at different places, while there are several replications of a specific file at different points. Replication is one of the most broadly studied phenomena in the distributed environments in which multiple copies of some data are stored at multiple sites where overheads of creating, maintaining and updating the replicas are important and challenging issues. Applications and architecture of distributed computing have changed drastically during last decade and so has replication protocols. Different replication protocols may be suitable for different applications. However, despite the importance of this issue, in a cloud environment as a distributed environment, this issue has not been investigated so far systematically. The data replication in the cloud environment falls into two categories of static and dynamic methods. In the static patterns, a number of created replicas is constant and fixed from the beginning. The number is either determined by the user from the beginning or the cloud environment determines such number. However, in the dynamic algorithm and considering its environment, the number is determined based on user’s access algorithm. The objective of this paper is to review the data replication techniques in these two main groups systematically as well as a discussing the main features of each group.
6- Conclusion This paper presented a systematic review of data replication. In this paper, we have reviewed the past and the state of the art mechanisms in the field of cloud data replication. Furthermore, we introduced a taxonomy of the reviewed cloud data replication mechanisms. Data replication in cloud environment increases the availability of data, Increased performance, and enhanced reliability by storing the data at more than one site, if a data site fails, a system can operate using replicated data, thus increasing availability and fault tolerance. At the same time, as the data is stored at multiple sites, the request can find the data close to the site where the request originated, thus increasing the performance of the system.
|
|
تصویری از مقاله ترجمه و تایپ شده در نرم افزار ورد |
|
|
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی | |
| عنوان فارسی مقاله: |
بررسی ادبی سیستماتیک روش های تکرار داده ها در محیط های ابری |
| عنوان انگلیسی مقاله: |
A systematic literature review of the data replication techniques in the cloud environments |
|
|
|