این مقاله انگلیسی ISI در نشریه آی تریپل ای در 13 صفحه در سال 2015 منتشر شده و ترجمه آن 31 صفحه میباشد. کیفیت ترجمه این مقاله ویژه – طلایی ⭐️⭐️⭐️ بوده و به صورت کامل ترجمه شده است.
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی | |
| عنوان فارسی مقاله: |
قیاس مبتنی بر تخمین تلاش: شیوه جدید برای کشف مجموعه شباهت ها از ویژگی های مجموعه داده |
| عنوان انگلیسی مقاله: |
Analogy-based effort estimation: a new method to discover set of analogies from dataset characteristics |
|
|
|
| مشخصات مقاله انگلیسی | |
| فرمت مقاله انگلیسی | |
| سال انتشار | 2015 |
| تعداد صفحات مقاله انگلیسی | 13 صفحه با فرمت pdf |
| نوع مقاله | ISI |
| نوع ارائه مقاله | ژورنال |
| رشته های مرتبط با این مقاله | مهندسی کامپیوتر و فناوری اطلاعات |
| گرایش های مرتبط با این مقاله | مهندسی نرم افزار ، مهندسی الگوریتم ها و محاسبات ، طراحی و تولید نرم افزار |
| چاپ شده در مجله (ژورنال) | موسسه مهندسی و فناوری نرم افزار – IET Software |
| ارائه شده از دانشگاه | دانشگاه غربی، لندن، کالیفرنیا |
| نمایه (index) | scopus – master journals – JCR |
| نویسندگان | Mohammad Azzeh – Ali Bou Nassif |
| شناسه شاپا یا ISSN | 1751-8806 |
| شناسه دیجیتال – doi | https://doi.org/10.1049/iet-sen.2013.0165 |
| ایمپکت فاکتور(IF) مجله | 2.097 در سال 2019 |
| شاخص H_index مجله | 40 در سال 2020 |
| شاخص SJR مجله | 0.318 در سال 2019 |
| شاخص Q یا Quartile (چارک) | Q3 در سال 2019 |
| بیس | نیست ☓ |
| مدل مفهومی | ندارد ☓ |
| پرسشنامه | ندارد ☓ |
| متغیر | ندارد ☓ |
| رفرنس | دارای رفرنس در داخل متن و انتهای مقاله ✓ |
| کد محصول | 11330 |
| لینک مقاله در سایت مرجع | لینک این مقاله در سایت IEEE |
| نشریه | آی تریپل ای – IEEE |
| مشخصات و وضعیت ترجمه فارسی این مقاله | |
| فرمت ترجمه مقاله | pdf و ورد تایپ شده با قابلیت ویرایش |
| وضعیت ترجمه | انجام شده و آماده دانلود |
| کیفیت ترجمه | ویژه – طلایی ⭐️⭐️⭐️ |
| تعداد صفحات ترجمه تایپ شده با فرمت ورد با قابلیت ویرایش | 31 صفحه با فونت 14 B Nazanin |
| ترجمه عناوین تصاویر و جداول | ترجمه شده است ✓ |
| ترجمه متون داخل تصاویر | ترجمه نشده است ☓ |
| ترجمه متون داخل جداول | ترجمه نشده است ☓ |
| ترجمه ضمیمه | ندارد ☓ |
| ترجمه پاورقی | ندارد ☓ |
| درج تصاویر در فایل ترجمه | درج شده است ✓ |
| درج جداول در فایل ترجمه | درج شده است ✓ |
| درج فرمولها و محاسبات در فایل ترجمه | به صورت عکس درج شده است ✓ |
| منابع داخل متن | به صورت عدد درج شده است ✓ |
| منابع انتهای متن | به صورت انگلیسی درج شده است ✓ |
| فهرست مطالب |
|
چکیده 1.مقدمه 2. مسئله پژوهش 3. آثار مرتبط 4.روش شناسی 4.1 پیشنهاد دو بخش کردن الگوریتم K-medoids 4.2. پیشنهاد روش شناسی K-ABE 4.3. طراحی تجربی 5. نتایج 6. بحث و بررسی و یافته ها 6.1. یافته ها 6.2. تهدید برای اعتبار 7. نتیجه گیری |
| بخشی از ترجمه |
|
چکیده برآورد تلاش مبتنی بر قیاس (ABE) به دلیل عملکرد فوق العاده و اداره مجموعه دادههای شلوغ یکی از روشهای کارآمد برای نرم افزار تخمین تلاش است. مدل مرسوم ABE معمولا از همان تعداد شباهتی استفاده میکند که برای رسیدن به تخمینهای خوب برای تمام پروژهها در مجموعه داده مناسب است. این نویسندگان ادعا میکنند که استفاده از همان تعداد شباهت ممکن است بهترین عملکرد کلی را برای تمام مجموعه داده تولید کنند اما لزوما بهترین عملکرد را برای هر پروژه منحصر به فرد تولید نمیکنند. بنابراین نیاز به درک بهتر ویژگیهای مجموعه داده به منظور کشف مجموعهای مطلوب از شباهتها برای هر پروژه به جای استفاده از یک شخص K نزدیک ترین پروژه وجود دارد. نویسندگان یک فن آوری جدید را پیشنهاد کردهاند که بر اساس دو بخش کردن الگوریتم خوشهایِ K-medoids به کار میآید تا با بهترین مجموعهای از شباهتها برای هر پروژهی منحصر به فرد قبل از پیش بینی استفاده شود. دو بخش کردنِ K-medoids ممکن است به درک بهتر ویژگی مجموعه داده، و خودکار پیدا کردن بهترین مجموعهای از شباهتها برای هر پروژهی آزمایشی مفید باشد. روش تخمین پیشنهاد شدهی آمار و ارقام عملکرد امیدبخش است و بهتر از سایر مدل های مرسوم ABE است.
1.مقدمه برآورد تلاش مبتنی بر قیاس(ABE) یک فرایند ساده شدهی پیدا کردن نزدیکترین شباهت بر اساس مفهوم بازیابی شباهت است]1-4[.این مسئله اظهار داشت که عملکرد پیش بینیِ ABE یک مجموعه دادهی وابسته است که در آن هر مجموعه داده نیاز به پیکربندی های مختلف و تصمیم گیری هایی در موردِ طراحی دارد]5-8[. انتشارات اخیر گزارش کرده است که مکانیزم تنظیم برای تولید تخمین بهتر در ABE مهم تر از مکانیزم بدونِ تنظیم است]1-9-10[. با این حال، با صرف نظر از نوع فنآوری تنظیم، روند کشف بهترین مجموعه ای از شباهتهای مورد استفاده قرار گرفته شده به عنوان کلید چالش است.
7. نتیجه گیری در این مقاله، ما مشکل کشفِ مجموعه ای مطلوب از شباهت ها را ارائه کرده ایم که توسط ABE به منظور ایجاد تخمین تلاش نزم افزاریِ خوبی استفاده می شود. با این حال، این مسئله را به خوبی به رسمیت شناخته که استفاده از تعداد ثابتی از شباهت ها برای تمام پروژه های آزمون برای به دست آوردن عملکرد پیش بینیِ بهتر کافی نیست. ما در مقاله ی خود چهار سوال پژوهشی را برای بررسی مشکل سنتی روش تنظیم ABE مطرح کردیم. که این روش ها شامل: (1) درک ساختار داده و (2) پیدا کردن روشی برای کشف خودکار مجموعه ای از شباهت ها است که برای هر پروژه ی واحد مورد استفاده قرار می گیرد. بنابراین ما یک روش جدید بر اساس به کار گرفتن الگوریتم خوشه ای BK و درجه واریانس مطرح کردیم. سپس به جای ارائه ی یک مقدار Kیِ ثابتِ پیش بینی شده به جای روش سنتیِ ABE، K-ABE راپیشنهاد کردیم که با تمام نمونه های آموزشی درون مجموعه داده شروع می شود، یاد گرفتنِ مجموعه داده برای شکل دادن به درخت دودوییِ BK است، به استثنای شباهت بی ربط بر اساس درجه واریانس و کشف مجموعه ای مطلوب از شباهت های K برای هر پروژه ی منحصر به فرد است. این روش پیشنهادی دارای قابلیت پشتیبانی از سایز های مختلفِ مجموعه داده است که خود دارای ویژگی های طبقه بندی شده ی زیادی است. هدف اصلی استفاده از درختِ BK بهبود بخشیدن به عملکردِ پیش بینیِ ABE است، از طریقِ موارد ذکر شده: (1) ساختن خود توسط کشف ویژگی های یک مجموعه داده ی خاص بر روی خودش، و (2) به استثنای پروژه های دور از مرکز بر اساس درجه واریانس. |
| بخشی از مقاله انگلیسی |
|
Abstract Analogy-based effort estimation (ABE) is one of the efficient methods for software effort estimation because of its outstanding performance and capability of handling noisy datasets. Conventional ABE models usually use the same number of analogies for all projects in the datasets in order to make good estimates. The authors’ claim is that using same number of analogies may produce overall best performance for the whole dataset but not necessarily best performance for each individual project. Therefore there is a need to better understand the dataset characteristics in order to discover the optimum set of analogies for each project rather than using a static k nearest projects. The authors propose a new technique based on bisecting k- medoids clustering algorithm to come up with the best set of analogies for each individual project before making the prediction. With bisecting k- medoids it is possible to better understand the dataset characteristic, and automatically find best set of analogies for each test project. Performance figures of the proposed estimation method are promising and better than those of other regular ABE models.
1 Introduction Analogy-based effort estimation (ABE) is simplified a process of finding nearest analogies based on notion of retrieval by similarity [1–4]. It was remarked that the predictive performance of ABE is a dataset dependent where each dataset requires different configurations and design decisions [5–8]. Recent publications reported the importance of adjustment mechanism for generating better estimates in ABE than null-adjustment mechanism [1, 9, 10]. However, irrespective of the type of adjustment technique followed, the process of discovering the best set of analogies to be used is still a key challenge.
7 Conclusions In this paper, we presented the problem of discovering the optimum set of analogies to be used by ABE in order to make good software effort estimates. However, it is well recognised that the use of fixed number of analogies for all test projects is not sufficient to obtain better predictive performance. In our paper we defined four research questions to address the traditional problem of tuning ABE methods: (1) understanding the structure of data and (2) finding a technique to automatically discovering the set of analogies to be used for every single project. Therefore we proposed a new technique based on utilising BK clustering algorithm and variance degree. Therefore rather than proposing a fixed k value a priori as the traditional ABE methods do, what k-ABE does is starting with all the training samples in the dataset, learning the dataset to form BK binary tree and excluding the irrelevant analogies on the basis of variance degree and discovering the optimum set of k analogies for each individual project. The proposed technique has the capability to support different size of datasets that have a lot of categorical features. The main aim of utilising BK tree is to improve the predictive performance of ABE via: (1) building itself by discovering the characteristics of a particular dataset on its own and, (2) excluding outlying projects on the basis of variance degree. |
|
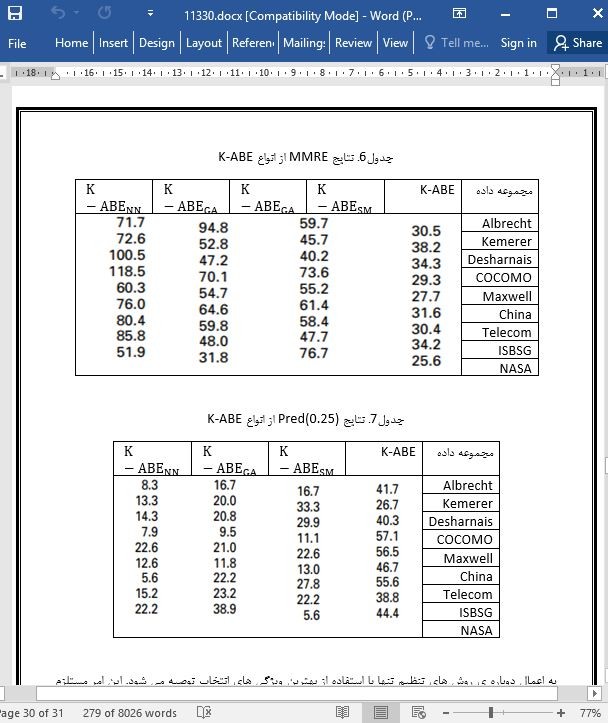
تصویری از مقاله ترجمه و تایپ شده در نرم افزار ورد |
|
|
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی | |
| عنوان فارسی مقاله: |
قیاس مبتنی بر تخمین تلاش: شیوه جدید برای کشف مجموعه شباهت ها از ویژگی های مجموعه داده |
| عنوان انگلیسی مقاله: |
Analogy-based effort estimation: a new method to discover set of analogies from dataset characteristics |
|
|
|