| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی
|
|
| عنوان فارسی مقاله: |
پیش بینی نقص نرم افزار با استفاده از الگوریتم خوشه بندی k-means بر مبنای خوشه بندی درختی |
| عنوان انگلیسی مقاله: |
Software Fault Prediction Using Quad Tree-Based K-Means Clustering Algorithm |
|
|
| مشخصات مقاله انگلیسی (PDF) | |
| سال انتشار | 2012 |
| تعداد صفحات مقاله انگلیسی | 5 صفحه با فرمت pdf |
| رشته های مرتبط با این مقاله | مهندسی کامپیوتر |
| گرایش های مرتبط با این مقاله | مهندسی نرم افزار |
| مجله | نتایج و یافته های بدست آمده در حوزه مهندسی دانش و داده |
| دانشگاه | گروه علوم و مهندسی کامپیوتر، موسسه تکنولوژی بیرلا، هند |
| کلمات کلیدی | خوشه بندی k-means، درخت Quad، پیش بینی نقص نرم افزار |
| شناسه شاپا یا ISSN | ISSN 1041-4347 |
| رفرنس | دارد |
| لینک مقاله در سایت مرجع | لینک این مقاله در سایت IEEE |
| نشریه | IEEE |
| مشخصات و وضعیت ترجمه فارسی این مقاله (Word) | |
| تعداد صفحات ترجمه تایپ شده با فرمت ورد با قابلیت ویرایش و فونت 14 B Nazanin | 15 صفحه |
| ترجمه عناوین تصاویر و جداول | ترجمه شده است |
| ترجمه متون داخل تصاویر | ترجمه نشده است |
| ترجمه متون داخل جداول | ترجمه نشده است |
| درج تصاویر در فایل ترجمه | درج شده است |
| درج جداول در فایل ترجمه | درج شده است |
| درج فرمولها و محاسبات در فایل ترجمه به صورت عکس | درج شده است |
- فهرست مطالب:
چکیده
مقدمه
کارهای مربوطه
مروری بر درخت Quad و مقدار دهی اولیه به الگوریتم فرضی
درخت Quad
مقدار دهی اولیه به الگوریتم فرضی
پارامترها و تعاریف
طرح آزمایشی
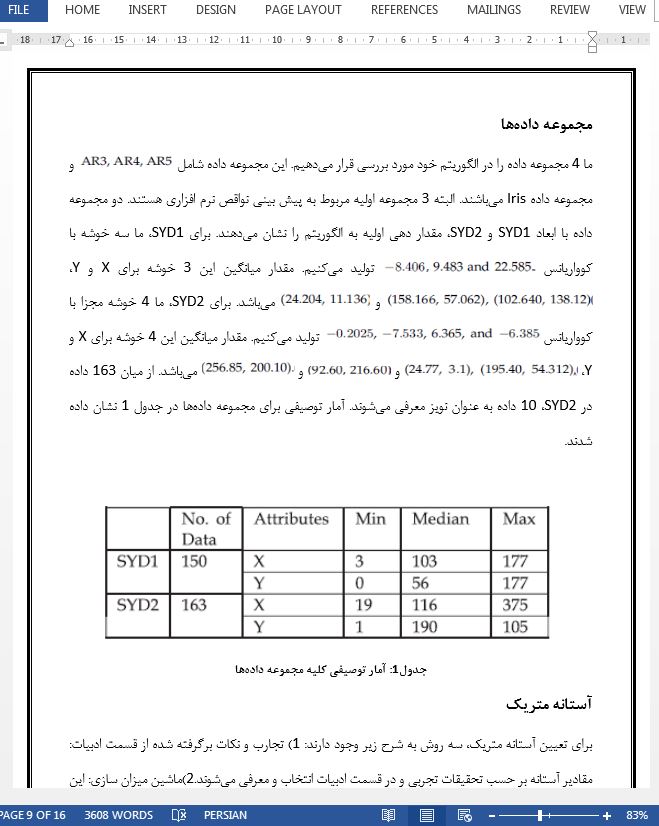
مجموعه داده ها
آستانه متریک
پارامترهای ارزیابی
Gain(تقویت)
تنظیم و نتایج آزمایشات
تحلیل نتایج
نتیجه گیری
- بخشی از ترجمه:
نتیجه گیری
ما در این مقاله اثر بخشی الگوریتم خوشه بندی K-means را برای پیش بینی ماژول نقص نرم افزار و برای مقایسه با الگوریتم کلی k-means مورد ارزیابی قرار دادیم. درخت Quad برای پیدا کردن نقاط مرکزی خوشه ها برای الگوریتم k-means مورد استفاده قرار گرفت. کاربر تمایل دارد تا تعداد خوشه های مورد دلخواه خود را با الگوریتم k-means تولید کند. الگوریتم درختی Quad به نقاط مرکزی خوشه ها، مقدار k می دهد که به عنوان ورودی الگوریتم k-means مورد استفاده قرار می گیرد. این امر با استفاده از تغییر در مقدار پارامتر آستانه که به عنوان ورودی برای الگوریتم درختی Quad محسوب می شود، به راحتی انجام خواهد شد. نرخ خطای کلی پیش بینی نقص نرم افزار در الگوریتم QDK با الگوریتم های دیگر در جدول 4 مقایسه شده است. در حقیقت در مورد مجموعه داده¬های AR4 و AR5، نرخ خطای کلی QDK با روش یادگیری نظارتی NB و DA قابل قیاس می باشد. نتایج جدول 5 نشان داد که الگوریتم QDK به عنوان الگوریتم بهینه( مقدار دهی اولیه در الگوریتم) انتخاب میشود. تعداد تکرار در الگوریتم K-means البته به استثنای AR5، کمتر از QDK میباشد و درصد خطای SSE دارای مقادیر قابل قبولی میباشد.
- بخشی از مقاله انگلیسی:
6 CONCLUSION
In this paper, we have evaluated the effectiveness of Quad Treebased K-Means clustering algorithm in predicting faulty software modules as compared to the original K-Means algorithm. Quad Trees are applied for finding the initial cluster centers for K-Means algorithm. In case the user intends to form a desired (sayK) number of clusters for K-Means algorithm, the Quad Tree-based algorithm can give K initial cluster centers to be used as input to the simple K-Means algorithm. This is facilitated by varying the value of the threshold parameter which is input to the Quad Tree algorithm. The overall error rates of software fault prediction approach by QDK algorithm are found comparable to other existing algorithms and are presented in Table 4. In fact, in the case of AR4 and AR5 data sets, the overall error rates of QDK are comparable with the supervised learning approaches NB and DA. The results of Table 5 show that the QDK algorithm works as an effective initialization algorithm. The number of iterations of K-Means algorithm is less in the case of QDK except for AR5, and the SSE as well as percent Error also give fairly acceptable values.
|
تصویری از مقاله ترجمه و تایپ شده در نرم افزار ورد |
|
|
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی
|
|
| عنوان فارسی مقاله: |
پیش بینی نقص نرم افزار با استفاده از الگوریتم خوشه بندی k-means بر مبنای خوشه بندی درختی |
| عنوان انگلیسی مقاله: |
Software Fault Prediction Using Quad Tree-Based K-Means Clustering Algorithm |
|
|