این مقاله انگلیسی ISI در نشریه آی تریپل ای در 9 صفحه در سال 2018 منتشر شده و ترجمه آن 23 صفحه میباشد. کیفیت ترجمه این مقاله ویژه – طلایی ⭐️⭐️⭐️ بوده و به صورت کامل ترجمه شده است.
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی | |
| عنوان فارسی مقاله: |
تشخیص بیماری آلزایمر در مجموعه داده های کوچک: چشم انداز انتقال دانش |
| عنوان انگلیسی مقاله: |
Detecting Alzheimer’s Disease on Small Dataset: A Knowledge Transfer Perspective |
|
|
|
| مشخصات مقاله انگلیسی | |
| فرمت مقاله انگلیسی | pdf و ورد تایپ شده با قابلیت ویرایش |
| سال انتشار | 2018 |
| تعداد صفحات مقاله انگلیسی | 9 صفحه با فرمت pdf |
| نوع مقاله | ISI |
| نوع ارائه مقاله | ژورنال |
| رشته های مرتبط با این مقاله | پزشکی و مهندسی کامپیوتر |
| گرایش های مرتبط با این مقاله | بیوانفورماتیک پزشکی، هوش مصنوعی |
| چاپ شده در مجله (ژورنال) | مجله انفورماتیک پزشکی و مهندسی پزشکی – Journal of Biomedical and Health Informatics |
| کلمات کلیدی | تشخیص به کمک کامپیوتر، مجموعه داده کوچک، سازگاری دامنه، بیماری آلزایمر، rs-fMRI، یادگیری ماشین |
| کلمات کلیدی انگلیسی | Computer-aided diagnosis – Small dataset – Domain adaptation – Alzheimer’s disease – rs-fMRI – Machine learning |
| ارائه شده از دانشگاه | دانشکده اتوماسیون، پردازش تصویر و کنترل هوشمند آزمایشگاه وزارت آموزش چین، دانشگاه علم و صنعت Huazhong، ووهان، چین |
| نویسندگان | Wei Li – Yifei Zhao – Xi Chen – Yang Xiao – Yuanyuan Qin |
| شناسه شاپا یا ISSN | 2168-2194 |
| شناسه دیجیتال – doi | https://doi.org/10.1109/JBHI.2018.2839771 |
| ایمپکت فاکتور(IF) مجله | 6.977 در سال 2020 |
| شاخص H_index مجله | 125 در سال 2021 |
| شاخص SJR مجله | 1.293 در سال 2020 |
| شاخص Q یا Quartile (چارک) | Q1 در سال 2020 |
| بیس | نیست ☓ |
| مدل مفهومی | ندارد ☓ |
| پرسشنامه | ندارد ☓ |
| متغیر | ندارد ☓ |
| فرضیه | ندارد ☓ |
| رفرنس | دارای رفرنس در داخل متن و انتهای مقاله ✓ |
| کد محصول | 11744 |
| لینک مقاله در سایت مرجع | لینک این مقاله در سایت IEEE |
| نشریه | آی تریپل ای – IEEE |
| مشخصات و وضعیت ترجمه فارسی این مقاله | |
| فرمت ترجمه مقاله | pdf و ورد تایپ شده با قابلیت ویرایش |
| وضعیت ترجمه | انجام شده و آماده دانلود |
| کیفیت ترجمه | ویژه – طلایی ⭐️⭐️⭐️ |
| تعداد صفحات ترجمه تایپ شده با فرمت ورد با قابلیت ویرایش | 23 (3 صفحه رفرنس انگلیسی) صفحه با فونت 14 B Nazanin |
| ترجمه عناوین تصاویر و جداول | ترجمه شده است ✓ |
| ترجمه متون داخل تصاویر | ترجمه نشده است ☓ |
| ترجمه متون داخل جداول | ترجمه نشده است ☓ |
| ترجمه ضمیمه | ندارد ☓ |
| ترجمه پاورقی | ندارد ☓ |
| درج تصاویر در فایل ترجمه | درج شده است ✓ |
| درج جداول در فایل ترجمه | درج شده است ✓ |
| درج فرمولها و محاسبات در فایل ترجمه | به صورت عکس درج شده است ✓ |
| منابع داخل متن | به صورت عدد درج شده است ✓ |
| منابع انتهای متن | به صورت انگلیسی درج شده است ✓ |
| فهرست مطالب |
|
چکیده 1. مقدمه 2. روش ها الف. روش تراز کردن فضای فرعی اصلاح شده ب. طبقه بندی کننده آنالیز تشخیصی 3. ست آپ آزمایش الف. جمع آوری داده ها و پیش پردازش ب. استخراج ویژگی ج. روش آزمایش 4. نتایج 5- بحث و گفتگو 6- نتیجه گیری منابع |
| بخشی از ترجمه |
|
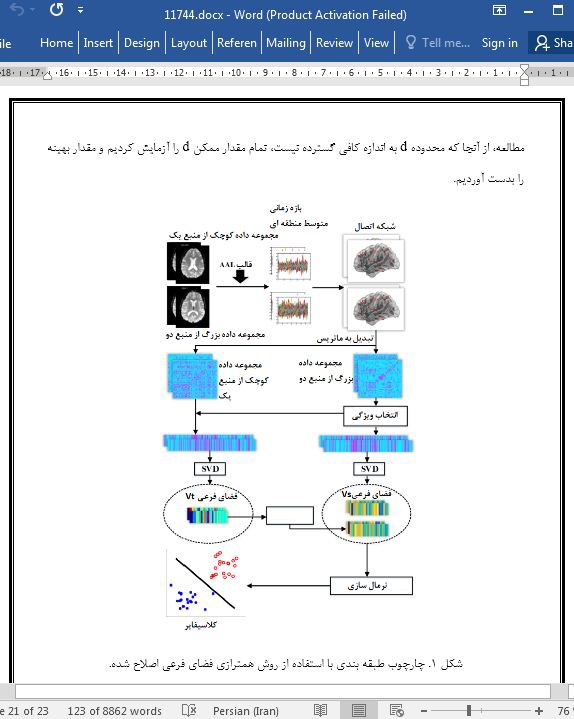
چکیده تشخیص به کمک کامپیوتر (CAD) موضوع جذابی در تحقیقات بیماری آلزایمر (AD) است. الگوریتم های بسیاری مبتنی بر مجموعه داده های آموزشی نسبتا بزرگ قرار دارند. با این حال، معمولا بیمارستان های کوچک نمی توانند نمونه های آموزشی کافی به منظور طبقه بندی توانمند جمع آوری کنند. اگر چه به اشتراک گذاری داده ها در تحقیقات علمی در حال گسترش است، اما مشخص نیست که آیا مدلی بر اساس یک مجموعه داده مناسب برای سایر منابع داده مطلوب است یا خیر. با استفاده از مجموعه داده کوچک یک بیمارستان محلی و مجموعه داده بزرگی که از اقدامات تصویر برداری بیماری آلزایمر (ADNI) به اشتراک گذاشته شده است، آنالیز ناهمگن انجام دادیم و دریافتیم که منابع داده تصویربرداری رزونانس مغناطیسی مرحله ای (fMRI) مختلف توزیع نمونه های متفاوتی را در فضای ویژگی نشان می دهند. علاوه بر این، روش انتقال دانش موثری را برای کاهش اختلاف در مجموعه داده های مختلف پیشنهاد دادیم و بهبود دقت طبقه بندی در مجموعه داده هایی با نمونه های آموزشی ناکافی پیشنهاد دادیم. دقت اینکار تقریبا به اندازه 20٪ در مقایسه با مدلی که تنها بر اساس مجموعه داده اصلی کوچک سخته شده بود، افزایش یافته است. نتایج نشان داد که رویکرد پیشنهادی، روش جدید و مؤثری برای CAD در بیمارستان هایی با مجموعه داده های آموزشی کوچک می باشد. این روش چالش اندازه نمونه محدود در تشخیص AD را بر طرف می کند، این چالش مشکل رایجی رایج است اما توجه کافی به آن نمی شود. علاوه بر این، این مقاله دیدگاه جدیدی را برای استفاده موثر از داده های چند منبع برای تشخیص بیماری های عصبی ارائه می دهد.
1. مقدمه مشکلات مرتبط با جمعیت افراد مسن به طور فزاینده ای جدی تر می شود، زیرا مردم بیشتر عمر می کنند و نرخ باروری در اکثر کشورها کاهش می یابد. علاوه بر این، چون غالب جمعیت افراد مسن هستند، افراد بیشتری در معرض خطر ابتلا به زوال عقل قرار دارند. در حال حاضر تقریبا 47 میلیون نفر در جهان زندگی می کنند که مبتلا به زوال عقل هستند، و پیش بینی می شود این تعداد تا سال 2050 بیش از 131 میلیون نفر افزایش یابد [1].
6- نتیجه گیری در این مقاله، ما نشان دادیم که وظیفه طبقه بندی AD با استفاده از یک مجموعه داده کوچک را می توان با استفاده از روش همترازی فضای فرعی اصلاح شده بهتر انجام داد. این روش می تواند به طور موثر دقت طبقه بندی در مجموعه های کوچک نمونه را بهبود بخشد. محققان می توانند از این روش برای از بین بردن چالش اندازه نمونه های بسیار محدود استفاده کنند، مخصوصا هنگامی که جمع آوری داده های تصویر برداری عصبی دشوار است و نیاز به تشخیص کامپیوتری با نمونه های محدود باشد. همچنین این مقاله می تواند به محققان کمک کند تا از داده های به اشتراک گذاشته شده بهتر استفاده کنند و تبادل داده جمع آوری شده را ارتقاء بخشند. |
| بخشی از مقاله انگلیسی |
|
Abstract Computer-aided diagnosis (CAD) is an attractive topic in Alzheimer’s disease (AD) research. Many algorithms are based on a relatively large training dataset. However, small hospitals are usually unable to collect sufficient training samples for robust classification. Although data sharing is expanding in scientific research, it is unclear whether a model based on one dataset is well suited for other data sources. Using a small dataset from a local hospital and a large shared dataset from the AD neuroimaging initiative, we conducted a heterogeneity analysis and found that different functional magnetic resonance imaging data sources show different sample distributions in feature space. In addition, we proposed an effective knowledge transfer method to diminish the disparity among different datasets and improve the classification accuracy on datasets with insufficient training samples. The accuracy increased by approximately 20% compared with that of a model based only on the original small dataset. The results demonstrated that the proposed approach is a novel and effective method for CAD in hospitals with only small training datasets. It solved the challenge of limited sample size in detection of AD, which is a common issue but lack of adequate attention. Furthermore, this paper sheds new light on effective use of multi-source data for neurological disease diagnosis.
I. INTRODUCTION THE problems associated with the aging population are becoming increasingly serious as people live longer and fertility rates decline in most countries. Furthermore, because a greater proportion of individuals are elderly, more people are at high risk of developing dementia. Currently, approximately 47 million people worldwide live with dementia, and this number is predicted to increase to more than 131 million by 2050 [1].
VI. CONCLUSION In this paper, we demonstrated that the AD classification task using a small dataset can be better solved using the modified subspace alignment method. This method can effectively improve the accuracy of the classification in small sample sets. Researchers can use this method to relieve the challenge of extremely limited sample size, particularly when collecting neuroimaging data is difficult and computer-aided diagnoses with limited samples are required. Our work may also assist researchers to make better use of shared data and promote the exchange of collected data. |
|
تصویری از مقاله ترجمه و تایپ شده در نرم افزار ورد |
|
|
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی | |
| عنوان فارسی مقاله: |
تشخیص بیماری آلزایمر در مجموعه داده های کوچک: چشم انداز انتقال دانش |
| عنوان انگلیسی مقاله: |
Detecting Alzheimer’s Disease on Small Dataset: A Knowledge Transfer Perspective |
|
|
|