این مقاله انگلیسی ISI در نشریه الزویر در 9 صفحه در سال 2018 منتشر شده و ترجمه آن 21 صفحه میباشد. کیفیت ترجمه این مقاله ویژه – طلایی ⭐️⭐️⭐️ بوده و به صورت کامل ترجمه شده است.
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی | |
| عنوان فارسی مقاله: |
تحلیل مقایسه ای هزینه های مکانیسم های تحمل خطا برای در دسترس بودن در ابر |
| عنوان انگلیسی مقاله: |
A comparative cost analysis of fault-tolerance mechanisms for availability on the cloud |
|
|
|
| مشخصات مقاله انگلیسی | |
| فرمت مقاله انگلیسی | pdf و ورد تایپ شده با قابلیت ویرایش |
| سال انتشار | 2018 |
| تعداد صفحات مقاله انگلیسی | 9 صفحه با فرمت pdf |
| نوع مقاله | ISI |
| نوع نگارش | مقاله پژوهشی (Research article) |
| نوع ارائه مقاله | ژورنال |
| رشته های مرتبط با این مقاله | مهندسی کامپیوتر |
| گرایش های مرتبط با این مقاله | مهندسی نرم افزار، رایانش ابری |
| چاپ شده در مجله (ژورنال) | محاسبات پایدار: انفورماتیک و سیستم ها – Sustainable Computing: Informatics and Systems |
| کلمات کلیدی | تحمل خطای فعال و انفعالی، پیش بینی خرابی، مهاجرت VM ، زمان بندی محدودیت ضرب الاجل، کمینه کردن انرژی |
| کلمات کلیدی انگلیسی | Reactive and Proactive fault-tolerance – Failure prediction – VM migration – Deadline constrain scheduling – Energy minimization |
| ارائه شده از دانشگاه | دانشکده فناوری و مدیریت، موسسه پلی تکنیک پورتو، فلگوئیراس، پرتغال |
| نمایه (index) | scopus – master journals – JCR |
| نویسندگان | Altino M – Sampaioa, Jorge G – Barbosa |
| شناسه شاپا یا ISSN | 2210-5379 |
| شناسه دیجیتال – doi | https://doi.org/10.1016/j.suscom.2017.11.006 |
| ایمپکت فاکتور(IF) مجله | 4.503 در سال 2020 |
| شاخص H_index مجله | 27 در سال 2021 |
| شاخص SJR مجله | 0.591 در سال 2020 |
| شاخص Q یا Quartile (چارک) | Q2 در سال 2020 |
| بیس | نیست ☓ |
| مدل مفهومی | ندارد ☓ |
| پرسشنامه | ندارد ☓ |
| متغیر | ندارد ☓ |
| فرضیه | ندارد ☓ |
| رفرنس | دارای رفرنس در داخل متن و انتهای مقاله ✓ |
| کد محصول | 11870 |
| لینک مقاله در سایت مرجع | لینک این مقاله در سایت Elsevier |
| نشریه | الزویر – Elsevier |
| مشخصات و وضعیت ترجمه فارسی این مقاله | |
| فرمت ترجمه مقاله | pdf و ورد تایپ شده با قابلیت ویرایش |
| وضعیت ترجمه | انجام شده و آماده دانلود |
| کیفیت ترجمه | ویژه – طلایی ⭐️⭐️⭐️ |
| تعداد صفحات ترجمه تایپ شده با فرمت ورد با قابلیت ویرایش | 21 (2 صفحه رفرنس انگلیسی) صفحه با فونت 14 B Nazanin |
| ترجمه عناوین تصاویر و جداول | ترجمه نشده است ☓ |
| ترجمه متون داخل تصاویر | ترجمه نشده است ☓ |
| ترجمه متون داخل جداول | ترجمه نشده است ☓ |
| ترجمه ضمیمه | ندارد ☓ |
| ترجمه پاورقی | ندارد ☓ |
| درج تصاویر در فایل ترجمه | درج شده است ✓ |
| درج جداول در فایل ترجمه | درج شده است ✓ |
| درج فرمولها و محاسبات در فایل ترجمه | به صورت عکس درج شده است ✓ |
| منابع داخل متن | به صورت عدد درج شده است ✓ |
| منابع انتهای متن | به صورت انگلیسی درج شده است ✓ |
| فهرست مطالب |
|
چکیده |
| بخشی از ترجمه |
|
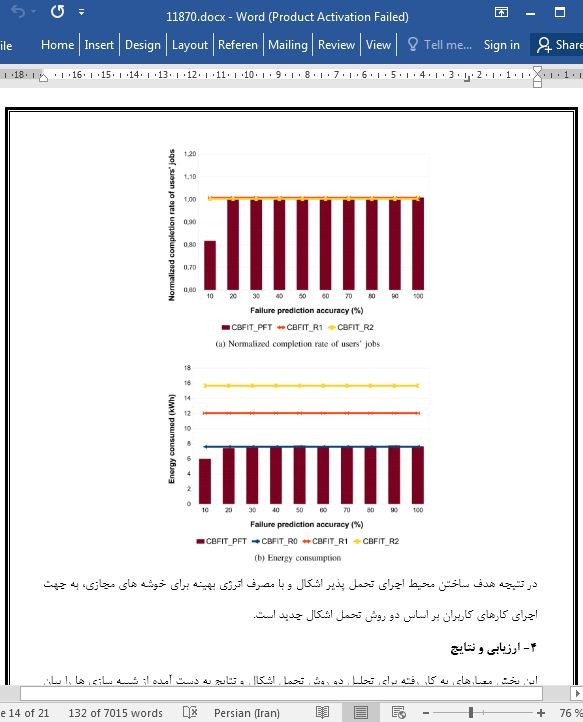
چکیده با رشد سایز و پیچیدگی مراکز داده برای پاسخدهی به تقاضای رو به افزایش منابع رایانشی، خرابی به جای یک خطا به یک هنجار تبدیل شده است. روشهای سنتی تأمین اتکاپذیری برای تحمل خطا، بر روی برنامه های نسخه برداری واکنش گرا تمرکز داشتند. در حالی که روشهای جدید بر روی نقطه بررسی / بازنشانی یک کار ( که می تواند در سیستمهای بزرگ باعث سربار زیادی شود) و بازنشانی به معنای تکرار یک کار است متکی هستند و در نتیجه منابع بیشتری را برای تامین قابلیت اعتماد و دسترس پذیری بالاتر استفاده می کنند. تحمل خطای کنش گرا در یک سیستم بزرگ راهکاری را برای اجتناب از خطا و بازیابی سیستم از حالت خطا فراهم می کند. اگرچه برنامه های تحمل خطا مختلف، محیطهای محاسبه اتکاپذیر مختلفی را برای هر دوی فراهم کننده و مشتری فراهم می کنند. در این مقاله دو روش جدید تحمل خطا از لحاظ دسترس پذیری محیط رایانش برای مشتری های ابر و هزینه انرژی برای فراهم کنندگان ابر با هم مقایسه شده است. نتایج نشان می دهد که روشهای فعال در معیار هزینه برای فرهم کننده ابر و خدمات رسانی به مشتری بر روشهای سنتی غلبه می کنند. اگرچه اتکاپذیری محیط رایانش فراهم شده توسط روشهای تحمل خطای کنش گرا بسیار وابسته به دقت پیش بینی خرابی است. 1 معرفی با توجه به روند موجود در اقتصاد مبتنی بر خدمات [1] که توسط زیرساختهای رایانشی توزیع شده مانند رایانش ابری پشتیبانی می شوند، نگرانی زیادی در مورد کیفیت و در دسترس پذیری خدمات ارائه شده وجود دارد. اگرچه فراهم کردن کیفیت خدمات (QoS) تضمین شده برای کاربران، یک کار بسیار دشوار و پیچیده است [2] چون تقاضای خدمات مصرف کنندگان در طول زمان تغییر می کند. این مشکل زمانی که دسترس پذیری گره پردازشی مد نظر باشد تشدید می شود. بر اساس تعریف یک سیستم دسترس پذیر است اگر میزان زمانهای از کار افتادن آن پایین باشد. حال یا به این دلیل که از رخداد کار افتادن آن نادر است و یا اینکه به سرعت بازنشانی می شود. بنابراین دسترس پذیری بخشی از قابلیت اعتماد است که بر اساس تعریف (IEEE) [3] قابلیت اعتماد، توانایی سیستم یا اجزا مورد نظر برای انجام عملکرد درخواست شده از آن تحت شرایط مشخص و در زمان مشخص است. قابلیت اعتماد را می توان به وسیله میانگین زمان بین دو خرابی ( از کار افتادن) (MTBF) اندازه گیری کرد که توسط سازنده اجزا تخمین زده می شود. 5 نتیجه گیری این مقاله تاثیرگذاری دو روش تحمل خطای پیشرفته که برای فراهم شدن فضای ابری قابل اتکا استفاده می شوند را ارزیابی کرده است. خرابی ها تهدیدی برای دسترس پذیری و قابلیت اتکای یک سیستم و خدمات ارائه شده است. متاسفانه با رشد زیاد مراکز داده بسیار بزرگ که برای پاسخدهی به تقاضاهای منابع رایانشی و خدمات ساخته می شوند، خرابی اجزا به جای یک خطا به یک هنجار تبدیل شده است. بنابراین موفقیت رایانش etascale/exascale نیازمند فراهم کردن قابلیت اعتماد و دسترس پذیری در مقیاسهای بزرگ است. روشهای تحمل خطا مختلفی برای حل این مسئله و تامین محیط رایانش اتکاپذیر وحود دارند. با این حال اتکا پذیری سیستم با هر هزینه ای یک راه حل نیست چون مصرف انرژی و در نتیجه هزینه های فراهم کننده را بالا می برد. |
| بخشی از مقاله انگلیسی |
|
Abstract As data centres continue to grow in size and complexity in order to respond to the increasing demand for computing resources, failures become the norm instead of an exception. To provide dependability at scale, traditional techniques to tolerate faults focus on reactive, redundant schemes. While the former relies on the checkpointing/restart of a job (which could incur significant overhead in a large-scale system), the latter replicates tasks, thus consuming extra resources to achieve higher reliability and availability of computing environments. Proactive fault-tolerance in large systems represents a new trend to avoid, cope with and recover from failures. However, different fault-tolerance schemes provide different levels of computing environment dependability at diverse costs to both providers and consumers. In this paper, two state-of-the-art fault-tolerance techniques are compared in terms of availability of computing environments to cloud consumers and energy costs to cloud providers. The results show that proactive fault-tolerance techniques outperform traditional redundancies in terms of costs to cloud users while providing available computing environments and services to consumers. However, the computing environment dependability provided by proactive fault-tolerance highly depends on failure prediction accuracy. 1 Introduction With trends in the service-oriented economy [1] being supported by distributed computing paradigms such as cloud computing, there is an increased concern about the quality and availability of offered services. However, providing quality of service (QoS) guarantees to users is a very difficult and complex task [2] due to the demands ofthe consumers’ services vary significantly with time. Moreover,this problem is exacerbated when one considers computing node availability. By definition, a system is available if the fraction of its down-time is very small, either because failures are rare or because it can restart quickly after a failure. Therefore, availability is a function of reliability, which, according to the Institute of Electrical and Electronics Engineers (IEEE) [3], is the ability of a system or component to perform its required functions under stated conditions for a specified period of time. Reliability can be measured by the mean time between failures (MTBF), which in turn is estimated by the component manufacturer. 5 Conclusion This paper has evaluated the effectiveness of two state-ofthe-art fault-tolerance mechanisms in providing dependable cloud services to consumers. Failures represent a threat to the availability and dependability of a system and services deployed. Unfortunately, with an ever-growing number of warehouse-sized data centres built to address the increasing demand for computing resources and services, component failures become the norm instead of an exception. As such, the success of petascale/exascale computing will depend on the ability to provide reliability and availability at scale. To address this problem, different fault-tolerance mechanisms exist to provide dependable computing environments. However, dependability of services at all costs is not a solution, as it may increase energy consumption and operational costs for providers. |
|
تصویری از مقاله ترجمه و تایپ شده در نرم افزار ورد |
|
|
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی | |
| عنوان فارسی مقاله: |
تحلیل مقایسه ای هزینه های مکانیسم های تحمل خطا برای در دسترس بودن در ابر |
| عنوان انگلیسی مقاله: |
A comparative cost analysis of fault-tolerance mechanisms for availability on the cloud |
|
|
|