این مقاله انگلیسی ISI در نشریه ساینس دایرکت (الزویر) در 24 صفحه در سال 2017 منتشر شده و ترجمه آن 48 صفحه میباشد. کیفیت ترجمه این مقاله ویژه – طلایی ⭐️⭐️⭐️ بوده و به صورت کامل ترجمه شده است.
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی | |
| عنوان فارسی مقاله: |
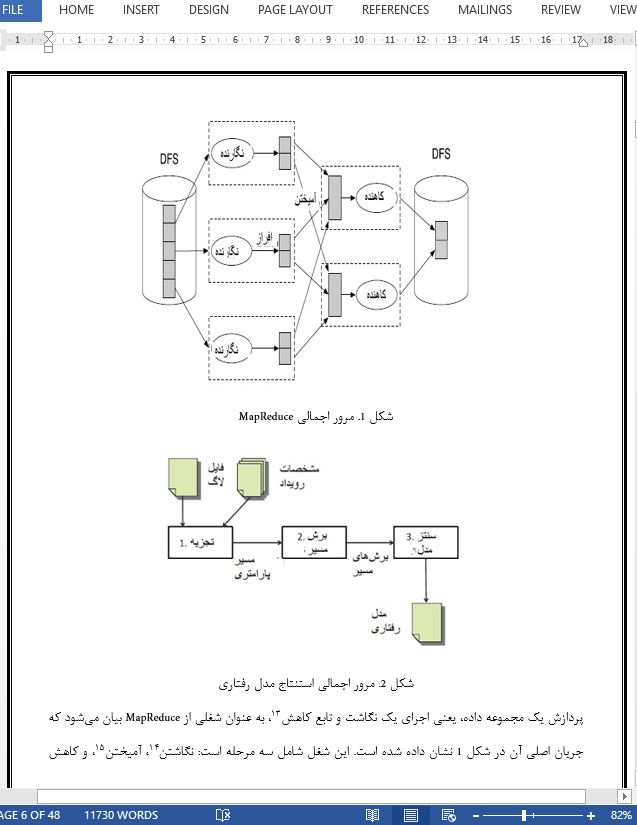
استنباط مدلهای رفتاری نرمافزار در نگاشت کاهش |
| عنوان انگلیسی مقاله: |
Inferring software behavioral models with MapReduce |
|
|
|
| مشخصات مقاله انگلیسی (PDF) | |
| سال انتشار | 2017 |
| تعداد صفحات مقاله انگلیسی | 24 صفحه با فرمت pdf |
| نوع مقاله | ISI |
| نوع نگارش | مقاله پژوهشی (Research Article) |
| نوع ارائه مقاله | ژورنال |
| رشته های مرتبط با این مقاله | مهندسی کامپیوتر |
| گرایش های مرتبط با این مقاله | مهندسی نرم افزار |
| چاپ شده در مجله (ژورنال) | علوم برنامه نویسی کامپیوتر – Science of Computer Programming |
| کلمات کلیدی | نگاشت کاهش، ردیابی پارامتری، استنتاج مدل، تجزیه و تحلیل لاگ |
| کلمات کلیدی انگلیسی | Model inference – Parametric trace – Log analysis – MapReduce |
| ارائه شده از دانشگاه | دانشگاه کالیفرنیا، ایروین، ایالات متحده آمریکا |
| نمایه (index) | Scopus – Master journals – JCR |
| نویسندگان | Chen Luo، Fei He، Carlo Ghezzi |
| شناسه شاپا یا ISSN | ISSN 0167-6423 |
| شناسه دیجیتال – doi | https://doi.org/10.1016/j.scico.2017.04.004 |
| ایمپکت فاکتور(IF) مجله | 1.939 در سال 2018 |
| شاخص H_index مجله | 59 در سال 2019 |
| شاخص SJR مجله | 0.317 در سال 2018 |
| شاخص Q یا Quartile (چارک) | Q3 در سال 2018 |
| بیس | نیست ☓ |
| مدل مفهومی | ندارد ☓ |
| پرسشنامه | ندارد ☓ |
| متغیر | ندارد ☓ |
| رفرنس | دارای رفرنس در داخل متن و انتهای مقاله ✓ |
| کد محصول | 10121 |
| لینک مقاله در سایت مرجع | لینک این مقاله در نشریه Elsevier |
| نشریه الزویر |  |
| مشخصات و وضعیت ترجمه فارسی این مقاله (Word) | |
| وضعیت ترجمه | انجام شده و آماده دانلود در فایل ورد و PDF |
| کیفیت ترجمه | ویژه – طلایی ⭐️⭐️⭐️ |
| تعداد صفحات ترجمه تایپ شده با فرمت ورد با قابلیت ویرایش | 48 صفحه (2 صفحه رفرنس انگلیسی) با فونت 14 B Nazanin |
| ترجمه عناوین تصاویر | ترجمه شده است ✓ |
| ترجمه متون داخل تصاویر | ترجمه شده است ✓ |
| ترجمه ضمیمه | ترجمه نشده است ☓ |
| درج تصاویر در فایل ترجمه | درج شده است ✓ |
| درج فرمولها و محاسبات در فایل ترجمه | به صورت عکس درج شده است ✓ |
| منابع داخل متن | به صورت عدد درج شده است ✓ |
| منابع انتهای متن | به صورت انگلیسی درج شده است ✓ |
| فهرست مطالب |
|
چکیده |
| بخشی از ترجمه |
|
چکیده در عملکرد جهان واقعی، سیستمهای نرمافزاری اغلب بدون توسعه هیچ مدل پیشفرض صریح ایجاد میشوند. این امر میتواند مسائلی جدی ایجاد کند که ممکن است مانع تکامل تقریبا اجتنابناپذیر آینده شوند، زیرا در بهترین حالت، تنها مستندسازی درباره نرمافزار، شکلی از تفاسیر کد منبع است. برای رفع این مشکل، تحقیقات باید روی استنتاج خودکار مدلها با استفاده از الگوریتمهای یادگیری ماشین برای اجرای دستورات متمرکز باشند. با این حال، دستورات (لاگهای) تولید شده توسط سیستم نرمافزاری واقعی ممکن است بسیار بزرگ باشند و الگوریتم استنتاج میتواند از ظرفیتی پردازش کامپیوتر منفرد تجاوز کند.
10- نتیجهگیری در این مقاله، رویکردی را برای استنتاج مدلهای رفتاری نرمافزاز از لاگهای بزرگ با استفاده از MapReduce ارائه میدهیم. در رویکرد ما لاگها در ابتدا تجزیه و برش داده میشوند و سپس مدل توسط الگوریتم توزیع شده k-دم استنتاج میشود. رویکرد ما را همچنین میتوان به عنوان پیشپردازشگر لاگ مورد استفاده قرار داد و با الگوریتمهای موجود استنتاج مدل ترکیب کرد. آزمایشات روی خوشههای آمازون و مجموعه دادههای بزرگ، کارایی و مقیاسپذیری رویکرد ما را نشان میدهند. این مقاله، کار قبلی ما [12] به چند روش توسعه میدهد. در این مقاله، به ویژه چند بهینهسازی عملی را شرح میدهیم، درستی رویکرد خود را به طور رسمی ثابت میکنیم، و ارزیابی آزمایشی کاملتری را تحت تنظیمات مختلف فراهم میسازیم. برنامه داریم که مطالعاتی موردی را روی لاگهای بزرگ تولید شده توسط سیستمهای نرمافزاری واقعی به منظور ارزیابی بیشتر عملکرد و قابلیت اجرا رویکرد خود انجام دهیم. همچنین به بحث موازیسازی الگوریتمهای دقیقتر استنتاج مدل یا ادغام محدودیتهای زمانی در طول مرحله استنتاج خواهیم پرداخت. |
| بخشی از مقاله انگلیسی |
|
Abstract In the real world practice, software systems are often built without developing any explicit upfront model. This can cause serious problems that may hinder the almost inevitable future evolution, since at best the only documentation about the software is in the form of source code comments. To address this problem, research has been focusing on automatic inference of models by applying machine learning algorithms to execution logs. However, the logs generated by a real software system may be very large and the inference algorithm can exceed the processing capacity of a single computer. This paper proposes a scalable, general approach to the inference of behavior models that can handle large execution logs via parallel and distributed algorithms implemented using the MapReduce programming model and executed on a cluster of interconnected execution nodes. The approach consists of two distributed phases that perform trace slicing and model synthesis. For each phase, a distributed algorithm using MapReduce is developed. With the parallel data processing capacity of MapReduce, the problem of inferring behavior models from large logs can be efficiently solved. The technique is implemented on top of Hadoop. Experiments on Amazon clusters show efficiency and scalability of our approach.
10- Conclusion In this paper, we presented an approach to infer software behavior models from large logs using MapReduce. In our approach, the logs are first parsed and sliced, then the model is inferred by the distributed k-tail algorithm. Our approach can also be used as a log preprocessor and combined with existing model inference algorithms. Experiments on Amazon clusters and large datasets show the efficiency and scalability of our approach. This paper extends our previous work [12] in several ways. Specially, we describe several practical optimizations, formally prove the correctness of our approach, and provide more complete experimental assessment under various settings. We plan to perform case studies on large logs generated by real software systems to further evaluate the performance and applicability of our approach. We also plan to investigate the parallelization of more accurate model inference algorithms or incorporating temporal constraints during the inference phase. |
|
تصویری از مقاله ترجمه و تایپ شده در نرم افزار ورد |
|
|
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی | |
| عنوان فارسی مقاله: |
استنباط مدلهای رفتاری نرمافزار در نگاشت کاهش |
| عنوان انگلیسی مقاله: |
Inferring software behavioral models with MapReduce |
|
|
|