گروه آموزشی ترجمه فا اقدام به ارائه ترجمه مقاله با موضوع ” زمینه ای بر اساس هادوپ جهت پردازش زبان طبیعی صفحات وب ” در قالب فایل ورد نموده است که شما عزیزان میتوانید پس از دانلود رایگان مقاله انگلیسی و نیز مطالعه نمونه ترجمه و سایر مشخصات، ترجمه را خریداری نمایید.
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی
|
|
| عنوان فارسی مقاله: |
پلتفرم مبتنی بر هدوپ برای پردازش زبان طبیعی اسناد و صفحات وب |
| عنوان انگلیسی مقاله: |
A hadoop based platform for natural language processing of web pages and documents |
|
|
| مشخصات مقاله انگلیسی (PDF) | |
| سال انتشار | 2015 |
| تعداد صفحات مقاله انگلیسی | 9 صفحه با فرمت pdf |
| رشته های مرتبط با این مقاله | مهندسی کامپیوتر و مهندسی فناوری اطلاعات |
| گرایش های مرتبط با این مقاله | اینترنت و شبکه های گسترده، مهندسی نرم افزار و رایانش ابری |
| مجله | مجله زبان ها و محاسبات ویژوال – Journal of Visual Languages and Computing |
| دانشگاه | سیستم های توزیع شده و آزمایشگاه فن آوری اینترنت، گروه مهندسی اطلاعات (DINFO)، دانشگاه فلورانس، ایتالیا |
| کلمات کلیدی | پردازش زبان طبیعی، هدوپ، برچسب زنی بخش گفتار، تجزیه متن، وب کرالینگ، ماینینگ بیگ دیتاها، محاسبه موازی، سیستم های توزیع شده |
| شناسه شاپا یا ISSN | 2015.10.017 ISSN |
| رفرنس | دارد |
| لینک مقاله در سایت مرجع | لینک این مقاله در نشریه Elsevier |
| نشریه | Elsevier |
| مشخصات و وضعیت ترجمه فارسی این مقاله (Word) | |
| تعداد صفحات ترجمه تایپ شده با فرمت ورد با قابلیت ویرایش و فونت 14 B Nazanin | 16 صفحه |
| ترجمه عناوین تصاویر و جداول | ترجمه شده است |
| ترجمه متون داخل تصاویر | ترجمه نشده است |
| ترجمه متون داخل جداول | ترجمه نشده است |
| درج تصاویر در فایل ترجمه | درج شده است |
| درج جداول در فایل ترجمه | درج شده است |
| درج فرمولها و محاسبات در فایل ترجمه به صورت عکس | درج شده است |
- فهرست مطالب:
چکیده
۱. مقدمه
۲. آثار مربوطه
۳. ساختار سیستم
۳-۱ MapReduce
۳-۲ Web crawler
۳-۳ استخراج کننده کلیدواژه/عبارات اصلی
۳-۴ کاربرد GATE
۳-۵ محاسبه ارتباط TF-IDF
۳-۶ ذخیره DB بیرونی
۴. ارزیابی
۵. نتیجه گیری و برنامه های آینده
- بخشی از ترجمه:
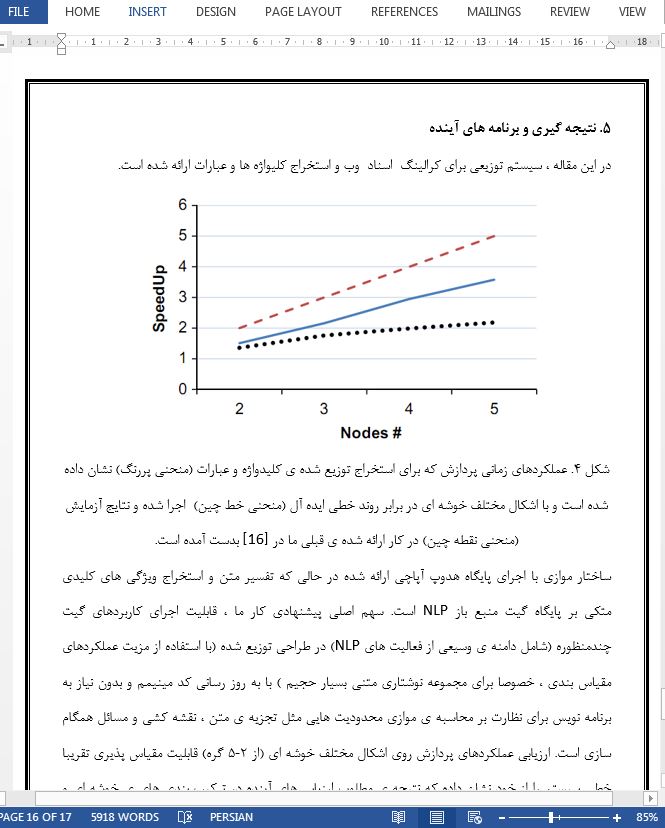
۵. نتیجه گیری و برنامه های آینده
در این مقاله ، سیستم توزیعی برای کرالینگ اسناد وب و استخراج کلیواژه ها و عبارات ارائه شده است.ساختار موازی با اجرای پایگاه هدوپ آپاچی ارائه شده در حالی که تفسیر متن و استخراج ویژگی های کلیدی متکی بر پایگاه گیت منبع باز NLP است. سهم اصلی پیشنهادی کار ما ، قابلیت اجرای کاربردهای گیت چندمنظوره (شامل دامنه ی وسیعی از فعالیت های NLP) در طراحی توزیع شده (با استفاده از مزیت عملکردهای مقیاس بندی ، خصوصا برای مجموعه نوشتاری متنی بسیار حجیم ) با به روز رسانی کد مینیمم و بدون نیاز به برنامه نویس برای نظارت بر محاسبه ی موازی محدودیت هایی مثل تجزیه ی متن ، نقشه کشی و مسائل همگام سازی است. ارزیابی عملکردهای پردازش روی اشکال مختلف خوشه ای (از ۲-۵ گره) قابلیت مقیاس پذیری تقریبا خطی سیستم را از خود نشان داده که نتیجه ی مطلوب ارزیابی های آینده در ترکیب بندی های ی خوشه ای و مجموعه داده های بزرگتر است . که در واقع نشان دهنده ی مسائل باز به روی کارهای آینده است. علاوه براین ، اجرای مدول استخراج کلیدواژه/عبارت اصلی روی محیط محاسباتی موازی دیگر ، مثل اسپارک ، کار جالبی است. علاوه براین ، برای ارتقای کیفی استخراج ویژگی های اصلی ، منابع دانش خارجی را می توان به کار برد، خصوصا چارجوب ها و مخازن معنایی ، تا تفسیر ویژگی های معنایی و ارتباط آنها فراهم شود.
- بخشی از مقاله انگلیسی:
5. Conclusions and future work
In this paper, a distributed system for crawling webdocuments and extracting keywords and keyphrases has been presented. The parallel architecture is provided byimplementing the Apache Hadoop platform, while textannotation and key features extraction rely on the NLPopens source GATE platform. The main contributionsoffered by our work is the capability of executing generalpurpose GATE applications (including a wide range of NLPactivities) in a distributed design (exploiting the benefitsof scaling performances, especially for very large textcorpora) with minimal code update and without the needfor programmers to care about parallel computing constraints,such as task decomposition, mapping and synchronizationissues. Evaluating processing performanceson different cluster configurations (from 2 to 5 nodes) hasshowed a nearly linear scalability of the system, which isan encouraging result for future assessments on even largerdatasets and cluster configurations. These actuallyrepresents open issues for future work. Moreover, it couldbe interesting to implement our keywords/keyphrasesextraction module on other parallel computing environment,such as the cited Spark. Furthermore, in order toimprove the quality of key features extraction, externalknowledge resources could be used, especially Semanticrepositories and frameworks, to allow the annotation ofsemantic features and relations.
|
تصویری از مقاله ترجمه و تایپ شده در نرم افزار ورد |
|
|
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی
|
|
| عنوان فارسی مقاله: |
زمینه ای بر اساس هادوپ جهت پردازش زبان طبیعی صفحات و اسناد وب |
| عنوان انگلیسی مقاله: |
A hadoop based platform for natural language processing of web pages and documents |
|
|