گروه آموزشی ترجمه فا اقدام به ارائه ترجمه مقاله با موضوع ” تصمیم گیری اتوماتیک با دیتابیس کثیف ” در قالب فایل ورد نموده است که شما عزیزان میتوانید پس از دانلود رایگان مقاله انگلیسی و نیز مطالعه نمونه ترجمه و سایر مشخصات، ترجمه را خریداری نمایید.
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی
|
|
| عنوان فارسی مقاله: |
کشف خودکار با استفاده از پایگاه داده های کثیف: کاربرد تشخیص سرطان پروستات |
| عنوان انگلیسی مقاله: |
Automatic Decision using Dirty Databases: Application to Prostate Cancer Diagnosis. |
|
|
| مشخصات مقاله انگلیسی (PDF) | |
| سال انتشار | 2010 |
| تعداد صفحات مقاله انگلیسی | 4 صفحه با فرمت pdf |
| رشته های مرتبط با این مقاله | مهندسی کامپیوتر و پزشکی |
| گرایش های مرتبط با این مقاله | ایمنی شناسی پزشکی، هوش مصنوعی و ادرارشناسی یا اورولوژی |
| مجله | کنفرانس بین المللی سالانه انجمن مهندسی پزشکی و زیست شناسی |
| دانشگاه | گروه پژوهشی محاسبات مهندسی بهداشت و Bioinspired ، دانشگاه آلیکانته، اسپانیا |
| شناسه شاپا یا ISSN | ISSN 1094-687X |
| رفرنس | دارد |
| لینک مقاله در سایت مرجع | لینک این مقاله در سایت IEEE |
| نشریه | IEEE |
| مشخصات و وضعیت ترجمه فارسی این مقاله (Word) | |
| تعداد صفحات ترجمه تایپ شده با فرمت ورد با قابلیت ویرایش و فونت 14 B Nazanin | 10 صفحه |
| ترجمه عناوین جداول | ترجمه شده است |
| ترجمه متون داخل جداول | ترجمه شده است |
| درج تصاویر در فایل ترجمه | ندارد |
| درج جداول در فایل ترجمه | درج شده است |
- فهرست مطالب:
چکیده
1 – مقدمه
A . شبکه های عصبی مصنوعی همانند دسته کننده ها
B . یکپارچه سازی داده ورودی: داده کلینیکی در برابر داده لابراتواری
II. آزمایش
A . پایگاه داده سرطان پروستات
B . مجموعه های داده کثیف و تکمییز
C . شبکه عصبی طراحی شده
D . فرایند های اموزش، صحه گذاری و تست
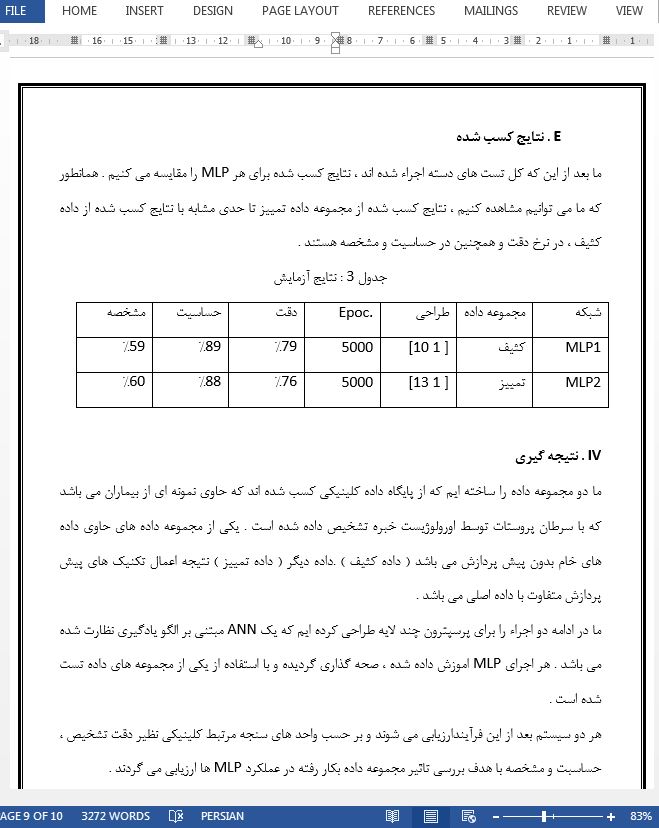
E . نتایج کسب شده
III. نتیجه گیری
- بخشی از ترجمه:
IV . نتیجه گیری
ما دو مجموعه داده را ساخته ایم که از پایگاه داده کلینیکی کسب شده اند که حاوی نمونه ای از بیماران می باشد که با سرطان پروستات توسط اورولوژیست خبره تشخیص داده شده است . یکی از مجموعه داده های حاوی داده های خام بدون پیش پردازش می باشد ( داده کثیف ) .داده دیگر ( داده تمییز ) نتیجه اعمال تکنیک های پیش پردازش متفاوت با داده اصلی می باشد .
ما در ادامه دو اجراء را برای پرسپترون چند لایه طراحی کرده ایم که یک ANN مبتنی بر الگو یادگیری نظارت شده می باشد . هر اجرای MLP اموزش داده شده ، صحه گذاری گردیده و با استفاده از یکی از مجموعه های داده تست شده است .
هر دو سیستم بعد از این فرآیندارزیابی می شوند و بر حسب واحد های سنجه مرتبط کلینیکی نظیر دقت تشخیص ، حساسبت و مشخصه با هدف بررسی تاثیر مجموعه داده بکار رفته در عملکرد MLP ها ارزیابی می گردند .
- بخشی از مقاله انگلیسی:
IV. CONCLUSION
We have built two data sets obtained from a clinical database that contains samples from patients who have been diagnosed with prostate cancer by an expert urologist. One of the data sets contains raw data without preprocessing (Dirty Data). The other‘s data (Clean Data) is the result of applying different preprocessing techniques to the original data. Next we have designed two implementations of a multilayer perceptron, which is an ANN based on the supervised learning paradigm. Each of the MLP implementations has been trained, validated and tested using one of the data sets. After this process, both systems are evaluated and compared in terms of clinically relevant metrics such as diagnosis accuracy, sensitivity and specificity, in order to check the influence of the data set used on the MLPs performance.
|
تصویری از مقاله ترجمه و تایپ شده در نرم افزار ورد |
|
|
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی
|
|
| عنوان فارسی مقاله: |
تصمیم گیری اتوماتیک با استفاده از دیتابیس کثیف: درخواست برای تشخیص سرطان پروستات |
| عنوان انگلیسی مقاله: |
Automatic Decision using Dirty Databases: Application to Prostate Cancer Diagnosis. |
|
|