گروه آموزشی ترجمه فا اقدام به ارائه ترجمه مقاله با موضوع ” انرژی کارایی برای مدیریت حافظه پنهان در پردازشگر ” در قالب فایل ورد نموده است که شما عزیزان میتوانید پس از دانلود رایگان مقاله انگلیسی و نیز مطالعه نمونه ترجمه و سایر مشخصات، ترجمه را خریداری نمایید.
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی
|
|
| عنوان فارسی مقاله: |
بررسی های انرژی عملکرد برای مدیریت کش (حافظه پنهان) به اشتراک گذاشته در پردازشگر چند هسته ای ناهمگن |
| عنوان انگلیسی مقاله: |
Performance-Energy Considerations for Shared Cache Management in a Heterogeneous Multicore Processor |
|
|
| مشخصات مقاله انگلیسی (PDF) | |
| سال انتشار مقاله | 2015 |
| تعداد صفحات مقاله انگلیسی | 25 صفحه با فرمت pdf |
| رشته های مرتبط با این مقاله | مهندسی کامپیوتر |
| گرایش های مرتبط با این مقاله | سخت افزار، معماری سیستم های کامپیوتری و رایانش ابری |
| کلمات کلیدی | چندهسته ای ناهمگن، خط مشی مدیریت کش، آخرین سطح کش، دور زدن |
| دانشگاه تهیه کننده | دانشگاه مینه سوتا |
| لینک مقاله در سایت مرجع | لینک این مقاله در سایت ACM |
| نشریه | ACM |
| مشخصات و وضعیت ترجمه فارسی این مقاله (Word) | |
| تعداد صفحات ترجمه تایپ شده با فرمت ورد با قابلیت ویرایش و فونت 14 B Nazanin | 42 صفحه |
| ترجمه عناوین تصاویر و جداول | ترجمه شده است |
| ترجمه متون داخل تصاویر | ترجمه نشده است |
| ترجمه متون داخل جداول | ترجمه نشده است |
| درج تصاویر در فایل ترجمه | درج شده است |
| درج جداول در فایل ترجمه | درج شده است |
| درج فرمولها و محاسبات در فایل ترجمه به صورت عکس | درج شده است |
- فهرست مطالب:
1 – مقدمه
2- چالش ها و فرصت ها
2-1 چالش ها در اشتراک LCC
2-2 بهبود اشتراک LCC
2-2-1 TLPدر دسترس به عنوان واحد سنجه زمان اجراء
3 – مدیریت LLC ناهمگن
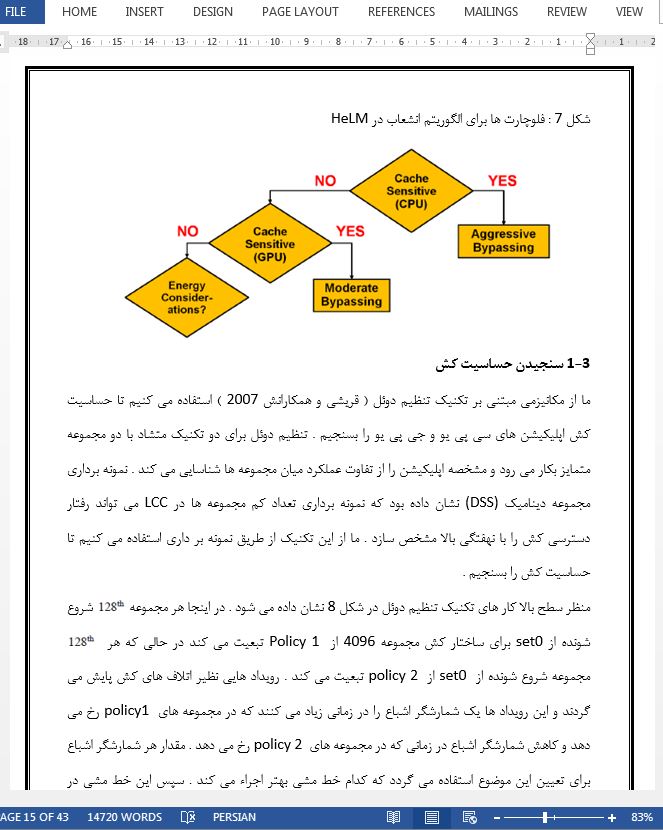
3-1 سنجیدن حساسیت کش
3-1-1 حساسیت LLC سی پی یو
3-2 تعیین آستانه موثر TLP
3-3 قرار دادن ان به همراه هم
3-4 دیگر ملاحظات طراحی
3-4-1 تاثیر بر انرژِ در تراشه و دسترسی دور از تارشه
3-4-2 کنترل ارتباط
4- روش شناسی آزمایشی
4-1 معیار ها
4-2 سیاست های مدیریت کش
4-2-1 مدیریت کش مبتنی بر استفاده مجدد
5- ارزیابی
5-1 واحد سنجه ارزیابی
5-2 عملکرد
5-2-1 تحلیل عملکرد دقیق
5-3 مقایسه با دیگر خط مشی ها
5-3 -1 DRRIP
5-3-2 . MAT/SDBP
5-3- 3 – TAP
5-4 حساسیت به اندازه کش
5-5 انواع حجم کار
5-6 سودمندی پهنای باند دور از تراشه
5-7 سربار سخت افزاری
6- مصرف انرژی
6-1 محصول تاخیر انرژی به توان دو
7- کار های مرتبط
7-1 مدیریت کش
7-2 پیشگو های بلوک مرده
- بخشی از ترجمه:
8- نتیجه گیری ها
اهمیت در حال رشد هسته های شتاب دهنده موازی داده نظیر جی پی یو به یکپارچه سازی اشان با هسنه های سی پی یو در قالب یکسان منجر شده بود . چنین معماری هایی با هسته های پرازش ناهمگن یک چالش مهم برای اشتراک بهینه منابع در تراشه نظیر LLC ارایه می کنند . مکانیزم مدیریت LLC ناهمگن ما یعنی HeLM بر TLP در دسترس در اپلیکیشن جی پی یو نظارت می کند و این اطلاعات را برای کنترل کردن دسترسی LLC جی پی یو در زمانی استفاده می کند ک اپلیکیشن برای حفظ نهفتگی دسترسی حافظه طولانی تر دارای TLP کافی باشد . حساسیت کش اپلیکیشن های سی پی یو و جی پی یو در حجم های کار ناهمگن توسط HeLMپایش می گردد و به اشتراک LLC دست می یابد که عملکرد کل سیستم و راندمان انرژی را بهبود می بخشد .
- بخشی از مقاله انگلیسی:
8. CONCLUSIONS
The growing importance of data-parallel accelerator cores, such as GPU, has lead to their integration with CPU cores on the same die. Such architectures with heterogeneous processing cores present a significant challenge to optimal sharing of on-chip resources such as the LLC. Our heterogeneous LLC management mechanism, HeLM, monitors the TLP available in the GPU application and uses this information to throttle the GPU LLC access when the application has enough TLP to sustain longer memory access latency. This in turn provides an increased share of the LLC to the CPU application, thus improving its performance. HeLM monitors the cache sensitivity of both CPU and GPU applications in heterogeneous workloads, and achieves LLC sharing that improves overall system performance and energy efficiency.
|
تصویری از مقاله ترجمه و تایپ شده در نرم افزار ورد |
|
|
| دانلود رایگان مقاله انگلیسی + خرید ترجمه فارسی
|
|
| عنوان فارسی مقاله: |
انرژی کارایی برای مدیریت حافظه پنهان به اشتراک گذاشته در پردازشگر چند هسته ای ناهمگن |
| عنوان انگلیسی مقاله: |
Performance-Energy Considerations for Shared Cache Management in a Heterogeneous Multicore Processor |
|
|